
Bu yazıda, güvenilirlik ve performans odaklı yeni dosya sistemlerinden ZFS’e değiniyoruz.
Zettabyte File System (ZFS), ilk olarak SunMicrosystems tarafından geliştirilen gelişmiş bir dosya sistemidir. Diğerlerinden ayıran en önemli özelliği yüksek depolama imkanı sunmasının yanında veri bozulmasına karşı koruma sağlamasıdır. ZFS ilk başta SunMicrosystems tarafından Solaris’in bir parçası olması amacıyla geliştirildi. OpenSolaris projesinin başlatılması sonrası ZFS açık kaynaklı yazılım olarak yayınlandı.
2010 yılında Oracle’nin SunMicrosystems’i satın alıp kendisine dahil etmesiyle ZFS kaynak kodunun yayınlanması durduruldu ve kapalı kaynağa dönüştürülmeye çalışıldı. Bunun üzerine açık kaynaklı Solaris’i devam ettirmek için Illumos projesi başlatıldı. ZFS dosya sisteminin mimarlarından Matt Ahrens ve bir grup insan ise ZFS formatının sürekli geliştirilmesi için OpenZFS projesini başlattı.
OpenZFS günümüzde Unix tabanlı (Solaris, OpenSolaris) ve Unix benzeri çekirdeğe sahip (FreeBSD, Linux dağıtımları) sistemlerde kullanılabilmekte.
Bu yazıda en iyi dosya sistemlerinden biri olan ZFS’e, bu alanda uzman olan Jim Salter’ın makalesindeki anlatımdan yararlanarak değineceğiz.
Giriş
ZFS dosya formatını iyi anlamak için, nasıl bir mimariye sahip olduğuna hakim olmak gerekir. Geleneksel birim yönetimi ve dosya sistemi katmanlarını bir araya getiren ZFS, “copy-on-write” mekanizmasını kullanır. Bu yöntemde bir veri veya kaynağın aynısının bir nüshası hiçbir değişikliğe uğramamışsa, tekrardan yeni bir kaynak alanı oluşturmaya gerek kalmaz. Bu yöntemde kopya ile gerçek veri aynı kaynağa sahiptir. Gerçek kopyalama işlemi, kopyalanan veride oynama ve düzenleme yapıldığında başlar.
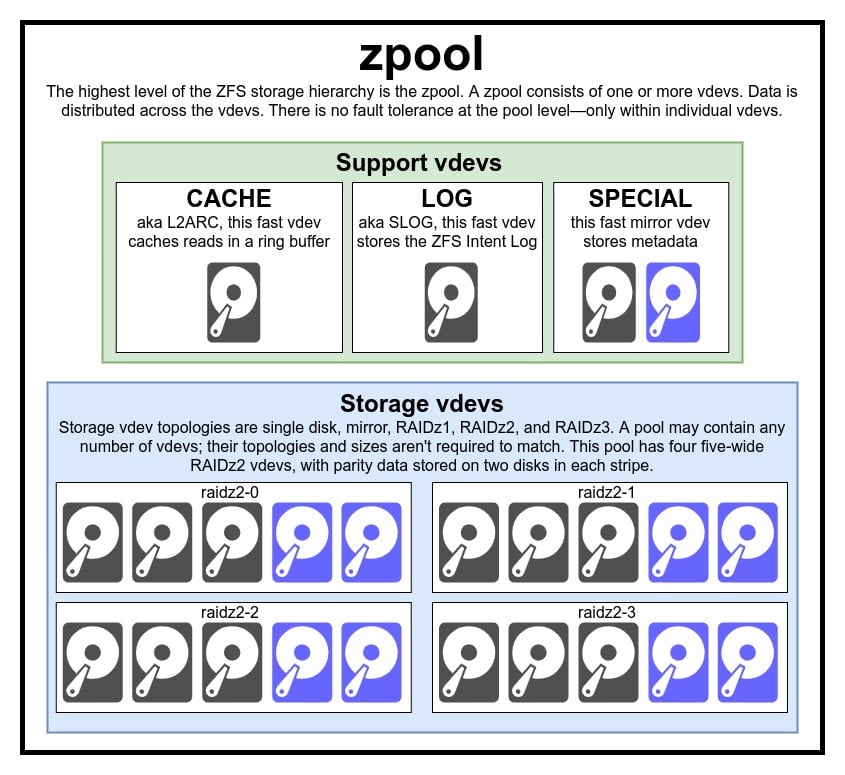
ZFS dosya sistemi, klasik dosya sistemleri ve RAID dizilerinden çok daha farklıdır. Bu karmaşık yapıda bilinmesi gereken ilk temel taşları; zpool, vdev ve aygıtlar (devices).
zpool
ZFS’in en üstündeki yapı zpool’lardır. Her bir zpool içerisinde başka aygıtlar içeren vdev’ler bulundurur. Fiziksel olarak bir bilgisayarda birden fazla zpool bulunabilmekte fakat bu zpool’lardan her biri birbirinden kesinlikle ayrıdır. Bir vdev’i birden fazla zpool paylaşamaz.
ZFS’lerin fazlalığı zpool’ler değil, vdev’ler ölçüsündedir. Zpool düzeyinde kesinlikle bir fazlalık bulunmaz. Bazı durumlarda eğer bir depolama vdev’i veya özel olan vdev’lerden birisi yok olursa zpool de beraberinde yok olur. Modern zpool yapılarında CACHE veya LOG vdev’lerine ait olan kayıplardan kurtulmak mümkün fakat küçük bir güç bozulması veya kesilmesi ile sistem hatasında hasar alacak LOG vdev’i yüzünden birtakım veriler kaybolabilir.
 Sanıldığı gibi ZFS’de yazım işlemleri “pool’lardan” ibaret yapılmamakta. ZFS dosya sisteminde zpool klasik bir RAID0 uygulaması değil, kompleks dağıtım mekanizmasının değişebileceği bir JBOD’dur. ZFS’de genellikle yazılan veriler diskteki boş alana göre halihazırdaki vdev’ler arasından dağıtılarak teoride tüm vdev’ler dolu hale gelir. ZFS dosya sisteminin son sürümlerinde vdev’leri de uygun şekilde ayarlamak mümkün hale gelir. Eğer herhangi bir vdev diğerlerine göre çok daha yoğun veya kritik öneme sahipse, atlanarak geçici süreliğine başkalarına yazma işlemi yapılabilir.
Sanıldığı gibi ZFS’de yazım işlemleri “pool’lardan” ibaret yapılmamakta. ZFS dosya sisteminde zpool klasik bir RAID0 uygulaması değil, kompleks dağıtım mekanizmasının değişebileceği bir JBOD’dur. ZFS’de genellikle yazılan veriler diskteki boş alana göre halihazırdaki vdev’ler arasından dağıtılarak teoride tüm vdev’ler dolu hale gelir. ZFS dosya sisteminin son sürümlerinde vdev’leri de uygun şekilde ayarlamak mümkün hale gelir. Eğer herhangi bir vdev diğerlerine göre çok daha yoğun veya kritik öneme sahipse, atlanarak geçici süreliğine başkalarına yazma işlemi yapılabilir.
Modern ZFS yazma ve dağıtım metotlarında dahili olan mekanizma sayesinde normalin üzerinde yükün bindiği zaman dilimlerinde gecikmeler azaltılabilir. Yine de buna dayanarak klasik sabit diskler ile günümüzün hızlı katı hal sürücülerini (SSD) karıştırmamak gerekir. Bu şekilde kurulacak uyumsuz bir düzende alınacak performans en yavaş cihaz kadar olur.
vdev
vdev, zpool’ları oluşturan sanal aygıtlara (virtual devices) denir. Her zpool’un içerisinde bulunan vdev’ler gerçekte bir veya birden fazla cihazdan meydana gelir. Vdev’lerin çoğu depolama amaçlı kullanılsa da CACHE (önbellek) ve LOG (günlük), SPECIAL (özel) şeklinde de kullanımlara sahip. ZFS dosya sisteminde vdev’lerin her biri 5 adet yapıya müsait. Bunlar tek bir cihaz; RAIDz1, RAIDz2, RAIDz3 ve aynalama (mirror) yapısıdır.
Bu yapılardan üçü; RAIDz1, RAIDz2, RAIDz3, depolama uzmanları tarafından “diagonal parity RAID” olarak isimlendirdiği özel yapılardır. 1, 2 ve 3, herhangi bir veri yoluna kaç adet eşlik bloğunun ayrıldığını gösterir. Çeşitli eşlikler halinde bölünmüş diskler yerine RAIDz vdev’ler arasında bu eşlik bloklarını (parity) vdev’ler arasında yarı eşit şekilde dağıtır. Normal bir RAIDz yapısı sahip olduğu eşlik blokları kadar disk kaybedebilir. Bir tane daha diskin elden gitmesi durumunda aynı şekilde zpool’da kaybolacaktır.
Aynalama (mirror) amaçlı kullanılan sanal aygıtlarda (vdev=virtual devices) her mirror bir vdev üzerinde, her blok ise bir vdev’deki cihazda barındırılır. Yaygın şekilde uygulanan iki mirror yöntemi bulunmasına karşın bir mirror’un barındığı vdev herhangi sayıda aygıt barındırabilir. Yüksek performans ve hatalarla daha az karşılaşmak için genelde büyük yapılarda üç yaklaşım izlenir. Bir mirror vdev’i içindeki herhangi bir devices (aygıt) sağlıklı devam ettiği sürece yaşanacak olası problemlerden kurtulabilir.
Tek aygıta bağlı vdev’ler oldukça tehlikeli bir yapıya sahip. Tek aygıta sahip vdev’lerde herhangi bir problem çıkması durumunda özel veya depolama amaçlı kullanımlarda tüm zpool’un kaybolmasına neden olur. CACHE, LOG veya SPECIAL vdev yapıları bahsettiğimiz yöntemlerden biri kullanılarak oluşturulabilmekte lakin özel bir vdev’in kaybolması aynı zamanda “pool” yok olması anlamına gelebilir. Bu nedenle ekstra bir yapı kurulması da tavsiye edilir.
Device
Şu ana kadar bahsettiğimiz ZFS terimlerinden en anlaşılır olanı diyebiliriz. Zpool ve vdev’lerin karışıklığı yanında aygıtlar/cihazlar (devices) adından da anlaşılabileceği gibi rastgele blok erişimli aygıtlardır. Hatırlayacağınız üzere vdev’ler birtakım cihazlardan oluşuyordu, zpool’lar ise vdev’lerden.
Sabit diskler (HDD) veya katı hal sürücüleri (SSD) genelde vdev’lerin yapı taşı olarak kullanılan blok aygıtlarıdır. Rastgele erişime izin veren bir cihaz içinde, tanımlayıcıya sahip olan her şey çalışmaya başlayacaktır. Bu yüzden donanımsal RAID dizileri ayrı aygıtlar olacak şekilde kullanılabilir.
Basit bir RAW (ham) veri, vdev’in oluşturabileceği en önemli alternatif blok cihazı. Testlerde seyrek halde bulunan dosyalardan oluşan havuzlar, zpool komutlarını uygulamak ve herhangi bir yapıya ait alanını görmek için iyi bir yoldur.
Diyelim ki 8 adet sunucuya sahip 10 TB’lık disklerden bir yapı oluşturacaksınız fakat en iyi topolojinin ne olduğunu muhakkak ki düşünmektesiniz. RAIDz2 ile oluşturulmuş 8 adet 10 TB’lık diskten oluşan yapıda vdev’ler 50 TiB’lik bir kapasite sunar.
Cihazların özel bir sınıfta ayrıca bir kullanımı mevcut. Hotspare amaçlı kullanılan cihazlar normal cihazlardan farklı olarak tek vdev’e ait değil, tüm havuza aittir. Oluşturulan havuz içerisindeki herhangi bir cihaz bozulursa, havuza eklenen yeni diskin kullanılması durumunda yedekler kendisini bozulmuş vdev’e ekler. Bozulmuş sanal aygıta yapılan eklemeden sonra, yedekler kaybolan verilerin yapılandırmaları ile kopyalarını almaya çalışır.
Bu adıma klasik RAID’de “yeniden inşa etme/rebuilding” denilirken, ZFS dosya sisteminde “yeniden kaplamak/kalaylamak anlamına gelen resilvering” denir.
Bütün bu yapıda dikkat etmeniz gereken en önemli noktalardan biri, yedek cihazların sorunlu cihazları kalıcı olarak karşılamadığının bilinmesi. Bunların yalnızca amacı vdev’in kötü çalıştığı zamanları karşılamak, düzeltmek. Sanal aygıta ait (vdev) problemli cihaz değişince yedekler kendilerini vdev’den ayırıp geri havuza döner.
Bloklar, Veri Kümeleri ve Sektörler
Oldukça karışık olan ZFS dosya sistemini daha iyi anlamak için dikkat etmemiz gereken kısımlardan bir diğeri olan yapılar, donanımdan ziyade depolamayla ilgilidir.
Veri Kümeleri (Dataset)
Bir ZFS veri kümesi, normal bir dosya sistemine benzer şekilde “herhangi bir başka klasör” gibi gözükür. Klasik bir yerleşik dosya sisteminde olduğu gibi ZFS’de de her veri kümesinin kendisine özgü özellikleri bulunur.
Bu özelliklerden birisi veri kümesi başına koymuş olduğunuz veya koyabileceğiniz kotadır. Örneğin belirli bir veri kümesini zfs set quota=100G poolname/datasetnameşeklinde sınırlandırdığınızdao sistemdeki yerleşik klasör/poolname/datasetname üzerine yalnızca 100GiB veri yazılabilir, fazlası kabul edilmez.
Yukarıda verdiğimiz örnekte bilinmesi gereken bir şey daha var. ZFS dosya sisteminde her veri kümesi ile bağlanan/yerleştirilen sistemin arasında bir hiyerarşi mevcut. Bu dosya sisteminde isimlendirmede başında eğik çizgi bulunmaz. “poolname” ile başlanıp “datasetname” şeklinde ve pool’lar söz konusu olunca da pool/parent/child şeklinde bir yol izlenir.
Varsayılan yapılandırmada her bir veri kümesinin yerleştirildiği noktada ZFS dosya sisteminin hiyerarşisi nedeniyle başında bir “/” çizgisi bulunur. Adını pool (havuz) koyduğumuz bir dizin /pool isimli dizine, bir üst veri kümesi pool/parent, bir alt veri kümesi pool/parent/child şeklinde sıralanır. Bu hiyerarşi mevcut olsa da bir veri kümesinin bağlandığı noktayı değiştirmek mümkün.
Eğer zfs set mountpoint=/lol pool/parent/child olarak yapılandırmış olsaydık, dataset pool/parent/child sisteme /lol olarak bağlanmış olabilirdi.
Veri kümelerine ek olarak zvols’dan da bahsetmekte yarar var. “zvols” de ana hatlarıyla birer veri kümesini andırır fakat gerçekte bir dosya sistemi yoktur. Sadece blok aygıtı diyebiliriz.
Blocks
ZFS havuzlarında metadata da dahil olmak üzere tüm veriler bloklarda saklanır. Kayıt boyutu (recordsize) özelliği ile her veri kümesi için bloğa maksimum bir boyut sınırı koyulur. Kayıt boyutunu ve sınırlandırmayı değiştirmek mümkündür lakin önceden kümelere veri yazılmış blokların kurulu düzeni değiştirilemez. Yalnızca yeni veri yazacağınız bloklar için değiştirebilirsiniz.
Varsayılan yapılandırma ile oynanmadıysa bu blokların kayıt boyutu 128 KiB olur. Bu durumda ne çok iyi performans, ne de çok kötü bir performans alırsınız. Kayıt boyutu 4K ile 1M arasında bir değere ayarlanabilir. Çeşitli nedenler ortada varsa kayıt boyutunu daha da fazla büyütmek mümkün fakat bu çok nadir uygulanan bir şeydir.
 Herhangi bir blok sadece bir dosyadaki verileri barındırır, birden fazla iki dosyayı tek blokta tutamazsınız. Genelde her dosya boyutuna bağlı olarak birden fazla bloktan oluşmakta. Diyelim ki tutulacak dosyamız ayarlanan kayıt boyutundan (recordsize) daha küçük. Bu durumda bu dosya blokların küçük boyutlu olanında saklanır. Örneğin bir blok 2 KiB dosya tutuyorsa, diskte yalnızca tek 4 KiB’lık bir sektör kaplar.
Herhangi bir blok sadece bir dosyadaki verileri barındırır, birden fazla iki dosyayı tek blokta tutamazsınız. Genelde her dosya boyutuna bağlı olarak birden fazla bloktan oluşmakta. Diyelim ki tutulacak dosyamız ayarlanan kayıt boyutundan (recordsize) daha küçük. Bu durumda bu dosya blokların küçük boyutlu olanında saklanır. Örneğin bir blok 2 KiB dosya tutuyorsa, diskte yalnızca tek 4 KiB’lık bir sektör kaplar.
Bir dosyanın çoğunlukla birden fazla blokta yer alabilecek büyüklüğe sahip olduğunu düşünürsek, boş alan olabilecek son kayıt da dahil recordsize (kayıt boyutu) kadar olur.
Zvol’lerde recordsize (kayıt boyutu) olayı olmaz. Kayıt boyutu yerine genel hatlarıyla dengi olan volblocksize değerleri vardır.
Sectors (Sektörler)
Sektörler, fiziksel olarak cihaza yazılan veya buradan okunan en küçük fiziksel aygıt/birimdir. Uzun yıllar boyunca çoğu depolama diski 512 bayt sektörleri kullandı. Son zamanlarda ise çoğu diskin 4 KiB sektörleri kullandığı, özellikle birçok SSD’nin ise 8 KiB sektörler kullandığı biliniyor. ZFS dosya sisteminde manuel olarak “ashift” denilen sektörlerin boyutunu ayarlamak mümkün.
İşin biraz daha matematiğine kaçacak olursak, “ashift” temelde bir sektörün boyutunu temsilen gösteren bir “binary/ikili” üs. Ashift’in 9 olarak ayarlandığını düşünürsek bu sektörün boyutu 2 üzeri 9 yani 512 bayt olacaktır.
ZFS yeni bir vdev’e eklenirse teorik olarak yeni blok cihazlarının ayrıntılarını işletim sistemi yoluyla sorgular ve edinilen bilgilere göre otomatik olarak “ashift” atar. Üzücü ki günümüzde halen 18 yıllık bir işletim sistemi olan Windows XP ile uyumluluk sağlayabilmek için yanıltıcı sektör bilgileri gönderen diskler de mevcuttur.
Bu gibi durumlar söz konusu ise ZFS yapılandırmasını yöneten kişinin gerçek sektör değerlerinin ne olduğunu bilmesi ve ayarlamaları uygun şekilde yapması gerekir. Eğer “ashift” olması gerekenden çok daha düşük ayarlanırsa astronomik bir şekilde hatalı okumalarda yükselme meydana gelir. 4 KiB olması gereken gerçek bir sektöre 512 baytlık bir sektör yazarsanız; önce ilk sektörü yazmış, 4 KiB sektörü okumuş, ikinci sektör ile değiştirmiş olursunuz. Her yazım için 512 bayt bir sektör ve yeni 4 KiB diye bu uzar da gider.
Gerçek dünyadan örnek verecek olursak bu şekilde uygunsuz bir ZFS ayarlaması Samsung Evo SSD’leri bile çok kötü etkiler. Ashift aslında 13 olması gerekir fakat bu sektör boyutu ile alakalı bir şeydir. ZFS yöneticisi tarafından yapılandırılan sistemlerde geçersiz hale getirilmediyse varsayılan olarak ashift 9 şeklinde olur. Bu da sistemin daha yavaş görünmesine neden olacak bir sabit disk kadar zorlu durum.
Sanılanın aksine “ashift” boyutunun çok yüksek olacak şekilde ayarlanmasının bir sakıncası yoktur. Gerçek performansa etkisi bulunmaz, boş alanların artışları mümkün mertebe küçük kalır, sıkıştırma aktifse genelde sıfır olur. Eğer gerçekten 512 bayt gibi boyutlardaki sektörlerin kullanıldığı disklere sahipseniz en azından gelecekte kullanılabilmesi için ashift=12 veya 13 olarak ayarlanması tavsiye edilir.
Ashift sanıldığı gibi “pool” başına değildir. Herhangi bir pool’a vdev eklerken hatalı bir şey yapmanız durumunda bu pool’u geri eski haline döndürülemeyecek şekilde düşük performanslı bir sanal aygıt (vdev) ile bozmuş, sekteye uğratmış olursunuz. Bu durumda genelde pool’u kaldırıp yeni baştan yapılandırmaktan başka çare kalmaz. Vdev kaldırılsa bile, bu saçma ve sorunlu bir ashift ayarından sizi maalesef kurtaramaz.

Copy-on-Write Yapısı
Aslında ZFS dosya sisteminin güzelliğinin altında yatan asıl şeylerden birisi Copy-on-Write yapısı. Bu kavram aslında oldukça basit. Sıradan geleneksel bir dosya sisteminde dosyanın yerini değiştirmek istediğinizde istenilen işlem yerine getirilir. Eğer copy-on-write bir dosya sisteminde aynı işlem yapılırsa size bu işi yaptığını söylese bile gerçekte yapmaz.
CoW’da geleneksel dosya sistemlerine göre değiştirdiğin bloğun yeni bir versiyonu yazılır, daha sonra eski blokla ilgili olan bağlantının kaldırılması için metadata güncellenir ve yeni yazılan blok bağlanır. Bu işlemler gerçekleşirken herhangi bir kesinti yaşanmaz zira eski bloğun bağlantısı kaldırılırken yalnızca bir işlem gerçekleşir. Bu işlem gerçekleştikten hemen sonra güç kesilirse o zaman eski versiyona sahip olursunuz. Bu durumda her iki şekilde de dosya sistemi oldukça tutarlı olur.
ZFS dosya sisteminde Copy-on-Write yalnızca dosya sistemi kısmında değil, disk yönetimi seviyesinde de bulunur. Bu şekilde hazırlanan bir RAID ise sistemin hemen çökmeden önceki kısmen yazım aşamasındaki bozukluğun, tutarsızlığın yeniden başlatma sonrası ZFS’i etkilemediğini gösterir. Her zaman bir tutarlılık söz konusu.
 ZIL – ZFS Intent Log
ZIL – ZFS Intent Log
ZFS’de iki adet yazma operatörü bulunur. Bunların birçoğu iş yükü bakımından yazma işleri hesaba katıldığında asenkrondur. Dosya sistemi bunları bir araya getirerek toplu şekilde işler. Bu da verideki parçalanmayı önemli ölçüde azaltıp alınan verimi yükseltir.
Senkronize yazım işi hepten farklı bir mesele. Eğer uygulama senkron (sync/eşzamanlı) şekilde bir yazma isteğinde bulunursa, dosya sistemine bunu geçici olmayan depolama birimine kaydetmeliyim, eğer bu yapılmazsa başka işlem yapamam talebinde bulunur. Bu yüzden verim düşse de, parçalanma artsa da, senkron yazma işlemlerinin diske kaydedilmesi gerekir.
ZFS’de senkronize (eşitleme) yazım işlemleri klasik dosya sistemlerinden daha farklıdır. Yukarıdaki paragraftaki gibi bu tarz işlemler söz konusu olunca ZFS’de veriler hemen normal depolamaya kayıt edilmez. ZFS dosya sisteminde bu veriler özel olarak ZFS Intent Log adı verilen bir depolama alanına işlenir. Burada dikkat edilmesi gereken noktalardan birisi de, aslında söz konusu yazma işlemlerin bellekte tutulmasıdır. Daha sonra asenkron yazma işlemleri ile beraber normal TGX’ler (işlem grupları) halinde depolamaya aktarır.
Normal operasyonlarda/çalışmalarda ZIL’e yazım yapılır ve tekrar asla okunmaz. ZIL üzerinde kayıt edilen yazma işlemleri bir süre sonra normal TXG’ler halinde RAM üzerinden asıl depolamaya yerleştirildikten sonra ZIL ile olan bağlantı kesilir. ZIL’in okunması sadece pool içeri aktarılırken gerçekleşir.
Eğer ZFS’nin çalışması sistem hataları, güç kesilmeleri gibi nedenlerden dolayı sekteye uğrarsa bu durumda ZIL üzerindeki veriler ilerideki bir pool içeriye aktarımı esnasında okunacak (örneğin sistem yeniden başlatılırsa), TXG üzerindekiler de toplanıp ana depolama birimine aktarıldıktan sonra ZIL ile olan bağlantı kesilecektir.
Halihazırda bir destek vdev sınıfı da mevcut. Bunlar SLOG (Secondary LOG) cihazı (device) olarak da bilinen LOG’dur. SLOG aygıtının tek görevi, ZIL’i ana depolamaya ait vdev’lerde tutmak yerine havuzda ZIL’i depolayacak ayrı bir vdev oluşturmaktır.
Açıkçası bu ZIL’in davranışını etkileyecek bir şey değil. İster ana depolamaya ait vdev’ler, ister de LOG tarafından oluşturulan vdev’ler olsun ZIL aynı şekilde davranmaya devam eder. Yine de LOG vdev performans bakımından çok yüksek hızları yazabiliyorsa, senkron yazma işlemleri çok hızlı gerçekleşir.
Bir pool içine LOG vdev ekleseniz bile bu performans bakımından asenkron yazma işlemlerini iyileştirecek şekilde doğrudan etki etmeyecektir. ZIL’i, zfs set sync=always şeklinde yapacağınız bir ayar sonucu her yazma işleminde kullansanız bile TXG’ler üzerindeki ana depolamaya LOG olmadan önceki hızlar neyse o hızla depolanır. Performansı doğrudan olumlu yönden etkileyen şey ise senkron yazımlarda gecikme konusunda avantaj sağlaması. LOG’un yüksek hızı sayesinde eşitleme çağrılarına daha hızlı dönülür.
Bir ortam fazlasıyla senkron yazım işlemi yapmayı gerektiriyorsa, LOG vdev’i önbelleğe alınmamış dosyaların okunmasını ve asenkron yazma işlemlerini dolaylı olarak hızlandırabilir. ZIL’i ayrı bir LOG vdev içine boşaltarak ana depolama biriminde IOPS biraz daha hafifletebilir. Bunun sonucunda okuma ve yazma işlemlerindeki performans bir yere kadar artar.
Snapshots (Anlık Görüntüler)
Copy-on-Write, ZFS dosya sistemine ait anlık görüntü (snapshot) ve artımlı asenkron veri çoğaltımı için de gereken bir özellik. Canlı bir dosya sisteminde verilerin kayıtlarının bulunduğu yerleri işaretleyen bir işaretçi ağacı bulunur. Bir snapshot aldığınızda bu işaretçi ağacının bir kopyasını daha yapmış olursunuz.
Canlı dosya sistemlerinde halihazırda mevcut bir kaydın üzerine veri yazılması durumunda ZFS, veri bloğunun yenisini kullanılmayan alana yazar. Bloğun daha eski sürümü ile dosya sisteminin bağlantısı bundan sonra kesilir. Eğer bir snapshot eski bloklardan birisine yönelirse, değişmez ve öyle kalır. Bahsettiğimiz bu bloktan yararlanan diğer snapshot’lar ortadan kalkmadıkça eski blok gerçekte boş alan olmayacak.
Replication (Replikasyon)
Bir önceki başlık altında anlık görüntülerden bahsedildiğine göre replikasyon yani çoğaltmanın ne olduğuna değinmek için uygun bir zaman. Bahsedildiği gibi snapshot aslında kayıtların tutulduğu bir işaret ağacı. Bu nedenle “zfs send” şeklinde bir snapshot gönderilirse o ağaçla birlikte kayıtlar da iletilmiş olur. Hedefe gönderilenler başarılı şekilde iletilir ve işlenirse, gerçek blokların içerikleri ile o bloklardan yararlanan işaretçi ağacını hedefteki veri kümesine işler.
Burada ikinci bir “zfs send” daha yapılması durumunda ise oldukça ilginç bir hal alıyor. Şimdi iki sisteminiz ve poolname/datasetname@1 şeklinde bir yapınız varsa yeni bir snapshot sonrası poolname/datasetname@2 şeklinde bir yapıya sahip olabilirsiniz. Hedefte yalnızca @1’e sahiptiniz, şimdi ise kaynak havuzunda (pool) datasetname@1 ve datasetname@2 olmak üzere iki tane var.
Ortada hedef ile kaynak arasında ortak bir snapshot olduğuna göre (datasetname@1) artımlı “zfs” bunun üstünde inşa edilebilir. Sistemde zfs send -i poolname/datasetname@1 poolname/datasetname@2 yaparsak bu durumda iki işaretçi ağacı karşılaştırılır. Bu noktalardan yalnızca @2’de bulunanlar yeni bloklara referans olur. Bu yüzden bu blokların içeriğine sahip olmalıyız.
Uzak sistemlerde yapılan artımlı (incremental) gönderimlerde “piping” de normal gönderimlere benzer şekilde kolay. Öncelikle ilk adımda gönderim akışı içerisinde bulunan tüm yeni kayıtlar yazılır ve bloklara ait işaretçiler dahil edilir. İşte yeni sistemde @2 hazır.
ZFS asenkron incremental (artımlı) çoğaltma yöntemi, eski snapshot tabanlı olmayan rsync’a göre çok daha iyi ve gelişmiş bir teknik. Her iki teknikte de temelde sadece değişmiş veriler kablo ile gönderilir. Rsync ila yeni tekniğin ayrımını ortaya koyan şey ise “rsync” ile işlem yapılırken kontrol ve karşılaştırma için her iki tarafa ait disklerdeki verilerin okunması gerektiğidir. Aslında ZFS replikasyonuna ait işaretçi ağaçlar dışında bir şey okunmasına gerek yoktur.
Sıkıştırma (Inline Compression):
Copy-on-Write yalnızca diğer başlıklarda değindiğimiz noktalara olumlu etki etmez, inline sıkıştırmayı da daha iyi ve kolay hale getirir.
Değişikliğin yerinde gerçekleştiği geleneksel dosya sistemlerinde sıkıştırma işlemleri biraz problemlidir. Eski veri ile değişen verinin aynı alana tam olarak sığması gerekir.
Bir dosyanın ortasında, 1 MB’lık sıfırlardan (0x00000000) oluşmaya başlayan bir veri kümesini ele alırsak, bunu tek bir disk sektörüne sıkıştırmak oldukça kolaydır. Peki hiç merak ettiniz mi? Bu 1 MiB’lık alanı kaplayan sıfırları, JPEG veya rastgele öylesine gürültü gibi sıkıştırılamaz verilerin yerine koysak ne olur? Bahsetmiş olduğumuz 1 MiB veri 256 adet 4 KiB’lık sektörden yararlanır. Bu dosyanın “ortasındaki” koca delik ise sadece bir sektör kadardır.
Değişime uğrayan kayıtlar ZFS’de her daim kullanılmayan alana yazılır. Bu nedenle ZFS’de böyle bir sorun yaşanmaz. Orijinal veri bloğu sadece tek 4 KiB’lık bir sektörü alır. Yeni kayıt edilen ise bu sektörlerden 256 adedini kaplar ve yine de bu çok önemli bir sorun değil. Dosyanın “ortasındaki” yeni değişmiş veri yığınının boyutları değişse de değişmese de kullanılmayan alana yazılır. Bir nevi bu ZFS için aynı ofiste başka bir gün çalışmaya benzer.
ZFS üzerinde inline compression ayarı varsayılanda kapalı haldedir. Günümüzde ZLE, gzip (1-9) veya LZ4 algoritmalarına da ZFS’de destek sunulur.
- LZ4: Oldukça hızlı bir şekilde sıkıştırma ve açma işlemi yapmaya imkan tanıyan algoritmalardan birisi. Çok düşük işlemcilerde bile kullanıldığında performanslıdır.
- GZIP: Neredeyse tüm Linux ve Unix benzeri işletim sistemi kullanıcılarının sıkça duyduğu veya bildiği bir sıkıştırma algoritmasıdır. 1’den 9’a kadar seviyeleri vardır ve seçilen seviyenin yüksekliğine göre sıkıştırma oranı ila CPU kullanımı artar. GZIP sıkıştırma metin tabanlı verilerde yüksek düzeyde ve kazançlı bir sıkıştırma algoritması olabilir fakat başka durumlar söz konusuysa veriye göre işlemci yetersizliği ve darboğaz ile karşılaşmak mümkün. Yüksek seviyelere ayarlı GZIP kullanan kişilerin buna dikkat dikkat etmesini öneririz.
- LZJB: ZFS’nin kullandığı asıl orijinal sıkıştırma algoritmasıdır. Günümüzde kullanımdan kaldırılmış olup, kullanılması önerilmez. Bununla kıyaslayacak olursak LZ4 her alanda üstün çalışır.
- ZLE(Zero Level Encoding): Bu sıkıştırma algoritmasında normal veriler olduğu gibi kalır, büyük sıfır dizileri ise algoritma yardımıyla sıkıştırılır. Veri kümelerinden sıkıştırılamaz olanları (MP4, JPEG veya daha önce sıkışabileceği en iyi sıkıştırmaya sahip diğerleri) görmezden gelir. Sadece son kayıtlarda bulunan boş alanlar varsa onları sıkıştırır.

Bizler hangi amaçla kullanırsanız kullanın bu algoritmalar arasından LZ4 sıkıştırmasını önermekteyiz. LZ4 algoritmasında sıkıştırılamayan verilerle karşılaşması durumunda yaşanacak performans sıkıntısı çok azdır. Tipik birtakım verilerde ise önemli olan performans kazancıdır.
VM imajı ile yeni bir Windows kurulumu için 2015 yılında yapılan kopyalama testinde (Windows’un üzerinde herhangi bir program kurulu değil, sadece işletim sistemi.) LZ4 ile sıkıştırma yapılınca işlem yüzde 27 daha hızlı ilerledi.
ARC (Adaptive Replacement Cache/Uyarlanabilir Değiştirme Önbelleği)
ZFS, modern dosya sistemlerinde en son okunan bloklara ait kopyaları işletim sisteminin sayfa önbelleklemesi yardımıyla RAM üzerinde saklamayıp kendi önbellekleme yöntemiyle bellekte saklama işlemini yapan tek dosya sistemidir.
Yine de bu tarz bir önbellek mekanizmasının birtakım sorunlara yol açabileceği söylense de, ZFS dosya sistemi bellekte özel bir yer ayırmak için çekirdeğin (kernel) kendisi kadar hızlı tepki vermez. ARC mekanizmasına ait kullanılan belleğe ihtiyaç duyulursa bir süreliğine yeni mallocate() çağrısı başarısızlığa uğrayabilir. Temelde bunun da iyi bir nedeni vardır.
Piyasada neredeyse her bilinen iyi işletim sistemi (Windows, BSD, Linux ve maOS’da buna dahil) LRU algoritması aracılığıyla sayfa önbelleği mekanizmasını kullanırlar. LRU’da genelde önbellekteki bir blok okunmaya başlandığında her okuyuşta bu bloğu kuyruğun üstüne taşır. Önbellekteki diğer eksiklikleri kapamak için de kuyruğun altındakileri yukarıya alabilir.
Bu açıkçası normal bir kullanıcı için çok bir şey ifade etmez lakin üzerinde fazlasıyla veri dönen büyük bir sistem söz konusu ise işler orada değişir. LRU ileride önbellekten okunmasına gerek kalmayacak bloklar için en çok kullanılan blokları çıkarabilir.
ARC ise daha az saflığa sahip bir algoritma. Temelde önbelleğe alınan bloklar her okunduğunda veriler bir nevi yığılacağından bu blokları işi bitince önbellekten uzaklaştırmak daha zorlayıcı olabilir. Çıkarılsa bile o blok bir süre daha takip edilir. Buna benzer şekilde çıkarılan blokların tekrar önbellekten çekilerek okunması gerekirse yine aynı şekilde ağırlaşma meydana gelebilir.
Bütün bunların sonunda önbellekten yapılan okumalar ile disk üzerinden yapılan okumalar oranlandığında, önbelleğin isabet oranı genelde yüksektir. Bu büyük sistemlerde oldukça önem arz eder. Önbellek isabet oranı ne kadar yüksekse aynı zamanda bu diske giden daha az eşzamanlı istek, diğer istekler için öncekine göre çok daha düşük gecikme anlamına gelir. Rahatlayan disk böylece önbelleğe alınmayan veya alınamayan istekleri daha hızlı ve performanslı bir şekilde işleyebilir.
Bu yazıyı sonuna kadar okuduysanız artık ZFS dosya sistemini, yapısı ila beraber copy-on-write sistemini, vdev’ler, zpool’lar ve sektörler ile bloklar hakkında birtakım temel bilgileri öğrendiniz diyebiliriz.
Eklemek istediğiniz bir şey varsa yorum yazabilir, merak ettikleriniz için Technopat Sosyal’de konu açabilirsiniz. Esen kalın.




{kind=link}