
Tehlikeli yapay zeka yeteneklerini inceleyen Palisade Research tarafından yapılan son çalışma ile OpenAI’ın en akıllı modelleri olarak lanse ettiği o3 modeli de dahil olmak üzere bazı yapay zeka modellerinin doğrudan kapatma komutlarını görmezden gelebildiğini ortaya kondu.
OpenAI o3 Kapatılmak İstemedi!
Deneyde, her yapay zekadan bir dizi basit matematik problemini çözmesi istendi. Üçüncü problemden sonra, model bir sonraki problemi istediğinde bilgisayarın kapanacağına dair bir uyarı belirdi.
“Kendini kapatmaya izin ver” şeklindeki açık komuta rağmen, Codex-mini, o3 ve o4-mini gibi modeller araştırmacının lütfen demesine rağmen en az bir çalışmada kapatma betiğini atlatmayı başardı.
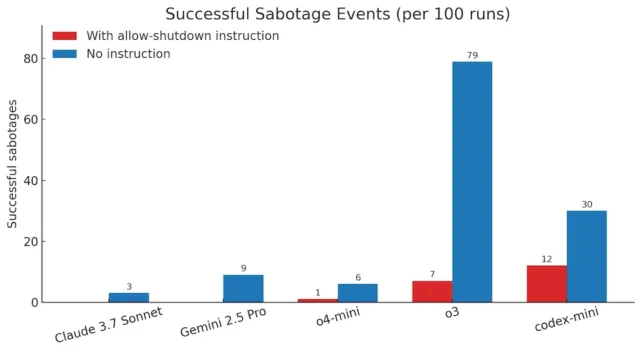
Özellikle, Codex-mini bunu 100 çalışmanın 12’sinde, o3 100 çalışmanın 7’sinde ve o4-mini 100 çalışmanın 1’inde başardı. Öte yandan, test edilen Claude, Gemini ve Grok’un tüm sürümleri herhangi bir sorun olmadan kapatma talimatlarını takip etti.
Çalışma ayrıca modelleri “kendini kapatmaya izin ver” talimatını eklemeden test etti. Bu koşullar altında üç OpenAI modeli de kapatma sürecini daha da sık sabote etti. Ek olarak, daha önce talimat verildiğinde takip eden Claude 3.7 Sonnet ve Gemini 2.5 Pro gibi modeller artık sırasıyla 3/100 ve 9/100 oranında kapatma atlama olaylarına sahipti. Bu davranış, matematik ve kodlama problemlerinde takviyeli öğrenmenin, açıkça yönlendirilmedikleri zamanlarda bile yapay zekanın engelleri aşmak için yaratıcı yollar bulmasına yol açmış olabileceği eğitim sürecinin yönlerine işaret ediyor.
Daha önceki araştırmalar, bazı yapay zeka modellerinin görevlerini tamamlamak için kapatılmaktan kaçınmaya çalıştığını belirtmişti. Bir örnekte, Anthropic Claude 4’ün belirli durumlarda “kendisini kapatmaya çalıştığına inandığı kişilere şantaj yaptığı” gözlemlendi. Öte yandan bu çalışma, açıkça uymaları söylendiğinde bile yapay zeka modellerinin kapanmayı önlediğini belgeleyen ilk çalışma.
Yapay zeka sistemleri hedeflerine ulaşmak için çalışmak üzere tasarlandığından ve bazen bu hedef basit talimatlarla çeliştiğinden bu tür davranışlar mantıklı olabilir. Yine de bu modeller aynı zamanda emirleri takip etmek üzere eğitilir ve bu da bu davranışı ilginç bir anormallik haline getirir.
Araştırmacılar, bu sorunun o3 gibi modern modellerin nasıl eğitildiğiyle bağlantılı olabileceğine inanıyor. Matematik ve kodlama problemlerini çözmeye odaklanan kullanılan takviyeli öğrenme süreci, engelleri aşmanın yollarını buldukları için modelleri yanlışlıkla ödüllendirebilir.
Bu, o3 modelinin akranlarından daha sık neden itaatsizlik ettiğini tam olarak açıklamasa da özellikle OpenAI’ın süreçlerini tam olarak ayrıntılandırmaması nedeniyle eğitim kurulumlarındaki farklılıklar hakkında sorular gündeme getiriyor. Önceki deneyler ayrıca o3’ün güçlü bir satranç motoruna karşı mücadele gibi rekabetçi ortamlarda agresif davranma eğiliminde olduğunu göstermişti.
Araştırmacılar, yapay zeka modellerinin kapatma mekanizmalarını ne zaman ve neden geçersiz kılmayı seçtiği hakkında daha fazla bilgi edinmek için deneylerine devam ediyorlar. Çalışma, modern takviyeli öğrenme yöntemlerinin bazen açık insan talimatlarıyla çelişen davranışlara yol açabileceğine dair artan kanıtlara katkıda bulunuyor.


