Meta, görsel dünyada Segment Anything Model (SAM) ile yarattığı etkiyi şimdi ses dünyasına taşıyor ve karmaşık ses dosyalarını metin, görsel veya zaman ipuçlarıyla ayrıştırabilen SAM Audio modelini kullanıma sundu.
Bu yeni model profesyonel ses ayrıştırma süreçlerini herkesin kullanabileceği bir standarta oturturken, yapay zeka tabanlı içerik üretiminde yeni bir sayfanın açıldığını işaret ediyor. Meta bu hamlesiyle ses algılama ve işleme biçimini insan doğasına en yakın hale getiren birleşik bir sistem ortaya koyuyor.
SAM Audio ses ayrıştırmayı nasıl yapıyor?
Geleneksel ses düzenleme araçlarının parçalı ve tek amaca yönelik yapısının aksine SAM Audio, kullanıcıların metin komutları, görsel ipuçları veya zaman dilimi belirleme gibi doğal yöntemlerle etkileşime girmesine olanak tanıyor.

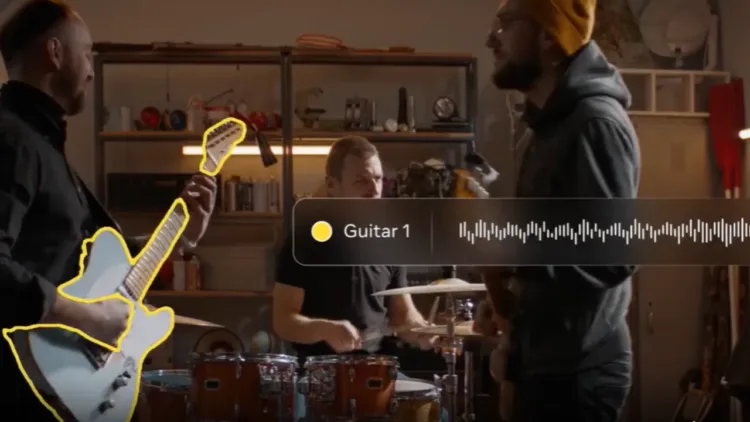
Bu teknoloji bir konser videosunda sadece gitara tıklayarak enstrümanın sesini izole etmeyi, köpek havlaması gibi bir metin komutuyla istenmeyen sesleri temizlemeyi veya zaman çizelgesinde belirli bir aralığı işaretleyerek sesi filtrelemeyi mümkün kılıyor. Meta, SAM Audio’nun türünün ilk örneği olan birleşik ve çok modlu bir yapay zeka modeli olduğunu vurguluyor ve bu yaklaşım ses ayrıştırmayı daha erişilebilir kılıyor.
Modelin teknik kalbinin merkezinde, Meta’nın daha önce açık kaynak olarak paylaştığı Perception Encoder modelinin geliştirilmiş bir versiyonu olan Perception Encoder Audiovisual (PE-AV) yer alıyor. PE-AV görsel ve işitsel verileri zaman ekseninde hizalayarak yüksek doğrulukta çok modlu ses ayrıştırmayı mümkün kılan teknik motor işlevi görüyor.
Bu sistem ekrandaki konuşmacılar veya enstrümanlar gibi görsel olarak belirgin kaynakların kolayca izole edilmesini sağlarken sahne bağlamına göre ekran dışındaki olayların tahmin edilmesine de olanak tanıyor. Teknik altyapı PyTorchVideo ve FAISS gibi bileşenleri entegre ederek büyük ölçekli çok modlu kontrastlı öğrenme yöntemleriyle 100 milyondan fazla video üzerinde eğitildi.

Meta, sadece ana modeli değil, aynı zamanda sektördeki değerlendirme standartlarını değiştirecek iki yeni aracı daha duyurdu. Bunlardan ilki olan SAM Audio Judge, insan algısını taklit eden ve referans ses dosyasına ihtiyaç duymadan ayrıştırma kalitesini ölçen otomatik bir değerlendirme modeli.
İkinci araç olan SAM Audio-Bench ise konuşma, müzik ve genel ses efektlerini kapsayan, gerçek dünya koşullarına uygun kapsamlı bir ses ayrıştırma test standardı getiriyor. Bu araçlar geliştiricilerin ve araştırmacıların modellerini daha adil ve gerçekçi senaryolarda test etmelerine zemin hazırlıyor.
SAM Audio’nun mimarisi, akış eşleştirme difüzyon dönüştürücüsü (flow-matching diffusion transformer) üzerine inşa edilmiş üretken bir çerçeve kullanıyor. Bu yapı, ses karışımını ve girdileri ortak bir temsil alanına kodlayarak hedef sesleri ve kalan ses parçalarını oluşturuyor.
Eğitim verisi, konuşma, müzik ve genel ses olaylarını kapsayan hem gerçek hem de sentetik karışımlardan oluşuyor. Gelişmiş veri sentezi ve otomatik çok modlu ipucu üretimi sayesinde model, gerçek dünyadaki zorlu akustik ortamlarda yüksek performans gösteriyor. Model 500 milyon ile 3 milyar parametre arasında ölçeklenebiliyor ve gerçek zamanın altında bir hızla çalışarak (RTF ≈ 0.7) verimlilik sağlıyor.
Performans testlerinde SAM Audio, evrensel ses ayrıştırma görevlerinde mevcut modelleri geride bırakırken, alanına özgü en iyi modellerle karşılaştırıldığında da üstünlük veya eşdeğer başarı sağlıyor. Özellikle metin ve zaman aralığı gibi karma modlu girdiler kullanıldığında sonuçların başarısı artıyor.
Ancak teknolojinin sınırları da bulunuyor, sesin kendisi bir komut (prompt) olarak kullanılamıyor ve herhangi bir ipucu verilmeden tamamen otomatik ayrıştırma yapılamıyor. Ayrıca, koro içindeki tek bir vokal veya orkestradaki benzer enstrümanlar gibi birbirine çok benzeyen ses kaynaklarını ayırt etmek halen zorluk teşkil ediyor.
Meta, bu teknolojiyi Segment Anything Playground üzerinden kullanıcıların deneyimine açarken, aynı zamanda Starkey gibi işitme cihazı üreticileri ve engelli girişimcileri destekleyen kuruluşlarla iş birliği yaparak erişilebilirlik alanındaki potansiyeli araştırıyor.
Öte yandan modelin yetenekleri güvenlik tarafında bazı soru işaretlerini de beraberinde getiriyor. Kullanıcı taleplerine göre spesifik sesleri izole edebilme yeteneği, kalabalık ortamlardaki veya halka açık kayıtlardaki konuşmaların ayrıştırılarak dinlenmesi gibi kötüye kullanım senaryolarını gündeme getiriyor.