
Google, Gemini 3 Flash modeli için Agentic Vision adını verdiği yeni görsel anlama yeteneğini duyurdu. Bu sistem, görsel akıl yürütmeyi doğrudan kod çalıştırma ile birleştiriyor ve verilen yanıtları görsel kanıta dayandırıyor.
Yeni yapı tek bakışta yorum yapan klasik görsel model yaklaşımı yerine görüntüyü adım adım inceleyen aktif bir araştırma süreci kullanıyor. Böylece seri numarası, uzak tabelalar ya da mikro detaylar gibi küçük unsurlar atlanmadan analiz ediliyor.
Agentic Vision ile görsel analiz süreci değişti
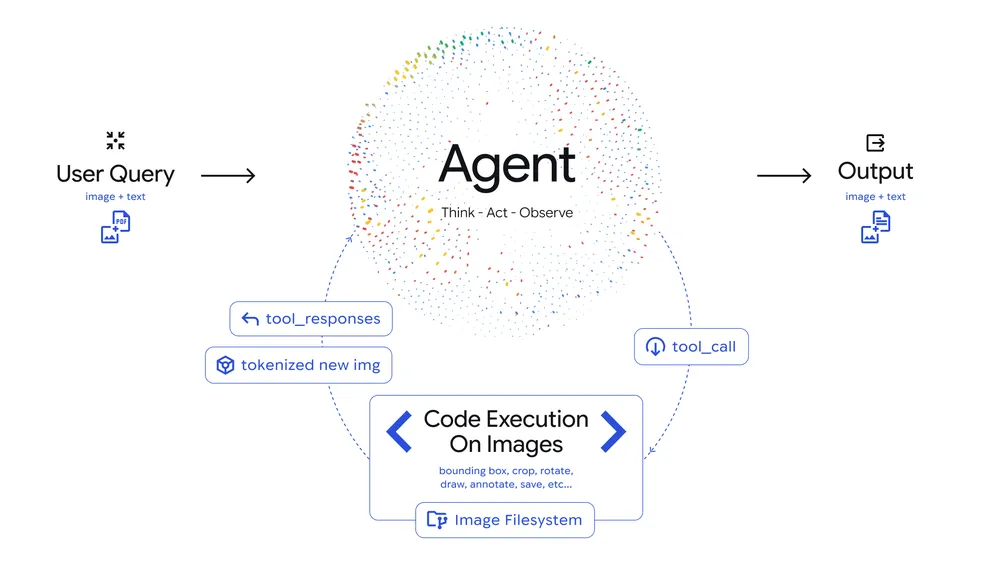
Agentic Vision, Gemini 3 Flash içinde görsel anlama sürecini statik değerlendirme yerine etken bir inceleme döngüsüne çeviriyor. Model, görsel ve kullanıcı sorgusunu birlikte değerlendiriyor, çok adımlı bir inceleme planı çıkarıyor ve ardından Python kodu üreterek görüntü üzerinde doğrudan işlem yapıyor.
Kırpma, döndürme, işaretleme, alan sayma ve hesaplama gibi işlemler kod yoluyla yürütülüyor. Ortaya çıkan yeni görseller modelin bağlam penceresine ekleniyor ve nihai yanıt bu genişletilmiş görsel kanıt üzerinden veriliyor.
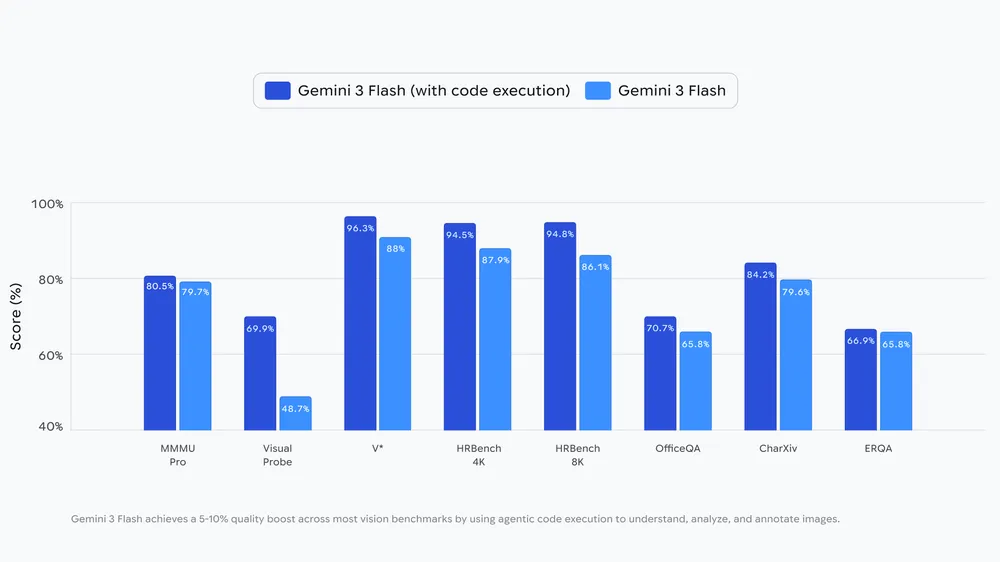
Kod çalıştırma özelliği aktif kullanıldığında, görsel kıyaslama testlerinin büyük bölümünde kalite skorunun yüzde 5 ile 10 arası arttığı bildiriliyor. Sistem Think, Act, Observe döngüsü ile ilerliyor.
İlk aşamada model sorguyu ve görseli analiz edip plan kuruyor. İkinci aşamada ürettiği Python kodunu çalıştırarak görüntüyü dönüştürüyor ya da ölçüyor. Son aşamada oluşan yeni çıktıyı tekrar inceleyip yanıtını netleştiriyor.
Agentic Vision, yüksek çözünürlüklü görsellerde küçük detaylara otomatik yakınlaşma davranışı da gösteriyor. Yapı planı doğrulama alanında kullanılan PlanCheckSolver platformunda bu yöntemle doğruluk oranının yüzde 5 yükseldiği paylaşıldı.
Model, çatı kenarları ve yapı bölümleri gibi alanları parça parça kırpıp yeniden bağlama ekliyor ve kurallara uygunluğu bu görsel kanıt üzerinden kontrol ediyor.
Görsel açıklama tarafında da farklı bir yaklaşım kullanılıyor. Model yalnızca gördüğünü tarif etmiyor, görüntü üzerine doğrudan çizim yapabiliyor. Örnek senaryoda bir eldeki parmak sayısı istenirken, model her parmak için kutu ve numara etiketleri çiziyor. Bu görsel taslak üzerinden sayım yapıyor ve sonucu buna göre veriyor. Böylece tahmin yerine piksel düzeyinde doğrulama kullanılıyor.
Yoğun veri içeren tablolar ve grafikler üzerinde de aynı yöntem geçerli. Model ham veriyi görselden çıkarıyor, Python ortamında normalize ediyor ve grafik üretiyor.
Matplotlib ile oluşturulan grafik çıktısı doğrudan yanıtın parçası oluyor. Çok adımlı görsel matematik işlemlerinde görülen tahmin hataları bu şekilde azaltılıyor.
Agentic Vision şu anda API üzerinden kullanıma açıldı. Geliştiriciler özelliği Google AI Studio ve Vertex AI üzerinden etkinleştiriyor. Gemini uygulamasında da kademeli dağıtım başladı ve model seçim alanında Thinking modu seçilerek erişiliyor. AI Studio Playground ortamında Tools bölümünde Code Execution anahtarı açılarak doğrudan test yapılabiliyor.
Google, sonraki güncellemelerde yakınlaştırma dışındaki davranışların da otomatik hale geleceğini, döndürme ve görsel matematik gibi işlemlerin açık komut gerektirmeden tetikleneceğini bildiriyor.
Ayrıca web araması ve ters görsel arama gibi yeni araçların da modele eklenmesi planlanıyor. Agentic Vision yeteneğinin ilerleyen dönemde Flash dışındaki model boyutlarına da genişletilmesi yer alıyor.


