
MMX, SSE ve AVX işlemci komut setlerine yakından bakıyoruz.
İşlemciler, birtakım komut setleri aracılığıyla yaptığımız işlemlerin elektriksel olarak karşılığını düzenleyen ve sistemin çalışmasını sağlayan en temel donanım. Bütün bu işlemler esnasında kullanılan komut setlerinden öne çıkanlar ise MMX, SSE ve AVX. Yeni nesil işlemcilerin de yaygınlaşması, bilgisayarların bilimsel süreçlerde veya çeşitli iş yüklerinde daha aktif kullanılmasıyla beraber süreci hızlandıran komut setleri daha da önem kazandı. Peki bu komut setleri ne işe yarıyor ve neden önemli?
Eski Zamanlarda İşlemciler ve Komut Setleri
Yıllar yıllar öncesine, 1980’lere kadar dönelim. Bir yandan işlemci pazarının lideri ve en büyüğü olan Intel, bir yandan da AMD’nin sıkı bir rekabet anlayışıyla piyasayı kavurduğu zamanlar, aynı günümüzde olduğu gibi. 8-bit yonga kullanan Commodore 64 gibi bilgisayarların aksine masaüstü tarafında “PC” adını verdiğimiz bilgisayarlar çok daha gelişmiş, 16-bit mimarisinden 32-bit yongalara hızlı bir geçiş süreci başlamıştı.
Mimarileri “bit” ile ifade ederken kullandığımız 16-bit, 32-bit, 64-bit gibi terimlerdeki sayılar aslında işlenebilecek verilerin büyüklüğü ve mimarinin gelişmişliğine dair bizlere fikir veriyor. Bu değerlerin büyüklüklerini 2’nin üssü cinsinden hesaplayabilirsiniz.
İşlemcilerin İşlediği Veri Tipleri
İşlemciler, yapıları gereği skaler veya tamsayı (integer) veri tiplerini kullanıyordu. Bunun ne olduğunu anlayabilmek matematiğin temel konularından birisine merhaba diyeceğiz. Buradaki anlamıyla skaler; yalnızca büyüklüğü ile belirlenebilen, herhangi matematiksel işlemin tek verinin değerleri kullanılarak gerçekleşmesine deniliyor. Kısaca tek talimat, tek veri (SISD, Single Instruction, Single Data) anlamına geliyor.
Yani o dönemin işlemcilerinin kullandığı komut biçimine bakacak olursak, iki veri değerinin birbirine eklenmesi işlemi, çalışma mantığından dolayı yalnızca bu iki sayı için gerçekleşiyor. Bahsettiğimiz aynı sayıyı, 16 adet sayının yer aldığı gruba eklemek için 16 adet komut vermeniz gerekiyor. O dönem için işlemcilerin genel itibariyle sınırları bu kadardı.
Ayrıca dönemin Intel 80386SX ve benzer işlemcileri tamsayı (örneğin 3 veya -5 gibi) tipindeki verileri işleyebiliyorken, kayar nokta (ondalık sayıları ifade ederken kullanılır, örneğin 5.80 veya 6.50 gibi) tipindeki sayıları işlemek için maalesef 80387SX gibi başka bir işlemciye ve işlemciye ne yapması gerektiğini söyleyen özel bir komut setine (instruction set) ihtiyaç duyuyordu.
O zamanın CPU’ları için, x86 komutları tamsayı hesaplamaları ve x87 ise float içindi; bugün, her ikisini de kapsayan x86 terimini kullanıyoruz, çünkü hepsi aynı çip tarafından yapılıyor.
Intel 80486, Yardımcı İşlemcileri Ortadan Kaldırıyor
Takvimler Nisan 1989’u gösterdiğinde Intel’in piyasaya I486 işlemci ailesinin ilk üyesi olan 80486’yı sürmesiyle beraber kayar noktalı veri tiplerinin işlenmesi için yardımcı işlemcilere gerek kalmamıştı. Bu işlemcilerin içerisinde kayar noktalı verilerin işlenebilmesi için gereken FPU (Floating Point Unit / Entegre Kayan Nokta Birimi) adında bir birim bulunuyor. Bu birim, işlemcide büyük bir alan kaplamasına rağmen performans anlamında ciddi avantaj sunuyor.
Her şeye rağmen 80486’dan sonra 1993’de piyasaya sürülen masaüstü işlemci ilk Intel Pentium’da dahil tüm yapı skalerdi, ta ki 3 yıl sonrasına, 1996 yılının Ekim ayına kadar.

MMX nedir?
Matematiksel olarak sayılar birtakım farklı şekillerde bir arada toplanabilir. Bu belirli gruplamaya vektör denilir. Daha da anlaşılır bir şekilde ifade edecek olursak yatay (horizontal) veya dikey (vertical) giden değerleri liste şeklinde düşünebilirsiniz. İşte MMX teknolojisiyle beraber işlemci dünyasında vektör matematiğinin yapılabilmesinin önü açıldı.
Bu teknoloji başlangıçta sadece tam sayı veri tiplerine uygun olduğu için oldukça sınırlıydı. Sistem aslında bunu yapmak için FPU için ayrılmış kayıtları kullanılıyordu. Bu nedenle vektörel matematiği kullanmak için bazı MMX komutları çalıştırıldığında aynı anda herhangi bir kayar nokta hesaplaması yapılamayacağını programcıların bilmesi gerekiyordu.
Pentium’un FPU’su 64 bit boyutunda kayıtlara sahipti ve MMX işlemleri için her biri iki 32-bit, dört 16-bit veya sekiz 8-bit tam sayı barındırabilirdi. Asıl vektör olan ise bu sayı grupları ve üzerlerinde işlenecek her talimat, gruptaki tüm değerler üzerinde yürütülüyor.
Masaüstü işlemcilerde kullanılan bu tip veri sistemine SIMD (single instruction, multiple data/tek talimat, çoklu veri) adı veriliyor. SIMD, masaüstü işlemcilerin geleceğe yönelik attığı en büyük adımlardan birisi olarak görülmekte.
Peki bu şekilde bir sistem kullanmanın avantajları nedir? Sayı gruplarına aynı hesaplamayı yapmayı içeren hemen hemen her şey, ancak en önemlisi 3B grafikler, multimedya ve genel sinyalleri işleme diyebiliriz.
Örneğin MMX, köşe işlemede matris çarpımını veya kroma anahtarlamada veya alfa birleştirmede iki video beslemesinin karıştırılmasını hızlandırmak için kullanılabilir.
Ne yazık ki, kayan nokta performansının olumsuz etkisi nedeniyle MMX kullanımındaki artış oldukça yavaştı. AMD, MMX ortaya çıktıktan yaklaşık iki yıl sonra, 3DNow! adlı kendi versiyonunu oluşturarak bu sorunu kısmen çözdü. Daha fazla SIMD talimatı sunuyordu ve kayan nokta sayılarını da işleyebiliyordu, ancak programcılar tarafından kabul edilmemekten muzdaripti.
Peki MMX adı? Intel’e göre hiçbir şeyi ifade etmiyor!
AMD, 3DNow ile Rekabeti Artırıyor
AMD tarafından bu sorunu çözmek ve rekabeti kızıştırmak adına 1998 yılında 3DNow! teknolojisi geliştirildi. İlk kez bu teknolojiyi kullanan AMD K6-2 işlemcilerde alışılageldik Intel işlemcilerden farklı olarak temel x86 komut setine SIMD komutları eklenerek vektörlerin çok daha verimli işlenmesi sağlandı.
MMX komut setinin gelişmiş versiyonu olarak düşünebileceğimiz AMD 3DNow!, MMX SIMD kayıtlarını (registers) tek duyarlı (32-bit) kayar nokta aritmetik işlemleri (toplama, çıkarma, çarpma) destekleyecek şekilde artırdı. Klasik yavaş x87 FPU yerine AMD 3DNow! destekli yazılımlar duruma bağlı olarak 4 kata kadar daha hızlıydı. Bu, AMD K6’nın rakibi Intel Pentium II işlemcisine nazaran daha iyi performans göstermesini sağlıyordu.
Yine de bu teknoloji yazılım dünyası tarafından pek rağbet görmedi ve yaygınlaşmadı.
Ağustos 2010 yılında da gelecekteki AMD işlemcilerde iki komut seti hariç (PREFETCH ve PREFECHW komutları: L1 önbelleğine en az 32 bayt veriyi önceden yükleyen) 3DNow!’un kaldırılacağı duyuruldu. Bu iki komut seti Intel Bay Trail mimarisini kullanan işlemcilerde de (ilgili mimariye sahip Atom, Celeron, Pentium) bulunuyor.

SSE’nin Doğuşu
1999’da Pentium III işlemcisinin piyasaya sürülmesiyle birlikte Intel için durumlar iyileşmeye başladı. Yeni vektör işleme özelliği SSE (Streaming SIMD Extensions) komut setiyle birlikte geldi. Üstelik bu sefer FPU’dakilerden ayrı, fazladan sekiz 128-bit kayıt seti ve kayan sayıları işleyebilecek ekstra bir komut seti yığını vardı.
Ayrı registerların kullanılması, FPU’nun artık çok fazla bağlı kalmayacağı anlamına geliyordu, ancak Pentium III, FP olanlarla aynı anda SSE talimatlarını işleyemiyordu. Yeni özellik ayrıca registerlarda yalnızca bir veri türünü destekliyordu: dört 32 bit kayan nokta.
Her şeye rağmen kayar nokta SIMD komutlarının sunulması ses ve görüntü işleme, video kodlama/kod çözme, dosya sıkıştırma ve çıkarma gibi birçok alanda büyük oranda performans artışı sağladı.
SSE2, SSE3 ve SSE4
Intel uzun vadede SSE teknolojisinden fazlasıyla yararlanmayı planladığı için bu teknolojiye çok fazla önem veriyordu. 2001 yılında Pentium 4 işlemcisi ile beraber SSE’nin yeni nesli olan SSE2 komut seti ortaya çıktı. SSE2’de farklı veri türlerinin işlenmesine yönelik destek çok daha iyi konumdaydı. Dört adet 32-bit veya iki adet 64-bit ondalık (float), aynı zamanda on altı adet 8-bit, 8 adet 16-bit, dört adet 32-bit veya iki adet 64-bit olmak üzere tamsayı (integer) tipinde veriler destekleniyordu. MMX yazmaçlar (register) halen işlemcide yer alsa da, bütün SSE ve MMX işlemleri ayrıca sunulan 128-bit SSE yazmaçları (register) ile değiştirilebiliyordu.
SSE3 ise 2003 yılında Pentium 4 işlemcisinin Presscott adı verilen yenilenmiş sürümü ile piyasaya sunuldu. SSE3 13 yeni komut (instruction) içeriyordu ve aynı yazmaç (register) üzerinde bulunan değerler arasında birtakım matematiksel işlemleri yapabilme yetisi kazanmıştı.
3 yıl sonra, Ocak 2006’da Intel tarafından Core işlemciler piyasaya sunuldu. Bu işlemciler sadece Pentium’ların yerini almakla kalmamış, SIMD teknolojisinin (SSSE3 -Supplemental SSE) nihai sürümü olan SSE4’e merhaba demişti. AMD tarafında da 2007 yılında çıkarılan Barcelona mimarisi kendisine özgü SSE4 komut setine sahipti.
SSE sürümüne yönelik küçük bir güncelleme daha 2008 yılında Nehalem mimarili Core işlemciler ile birlikte yayınlandı ve Intel tarafından SSE4.2 olarak adlandırıldı. (Orijinal sürüm aslında bundan dolayı SSE4.1 olarak da biliniyor.) SSE4.2’de yazmaçlarda herhangi bir değişiklik meydana gelmedi fakat daha fazla talimat (instruction) eklenerek mantıksal ve matematiksel işlemlerin önü geleceğe dönük olarak fazlasıyla açıldı.
2008 yılının sonlarında artık masaüstü işlemci pazarında hem Intel hem de AMD, MMX’i SSE4.2 komut setiyle işleyen işlemciler piyasaya sunuyordu. Günümüzde başta oyunlar olmak üzere birçok yazılımın bu komut setinden fazlasıyla faydalandığını söyleyebiliriz.

Yenilik Zamanı: AVX Doğuyor
Intel, 2008 yılında o ana kadar geliştirdiği SIMD yapısında büyük oranda bir değişiklik yapmak üzere sıkı bir şekilde çalıştığını duyurdu. 2011 yılında Sandy Bridge işlemciler AVX (Advanced Vector Extensions) komut setiyle beraber bilgisayar dünyasına sunuldu.
Her şey ikiye katlanmıştı. Sandy Bridge, iki kat daha fazla vektör yazmaçları ve iki kat daha büyük bir yapıyla bizleri karşılıyordu. On altı 256-bit yazmaç, yalnızca sekiz adet 32-bit veya dört 64-bit kayan sayı alabiliyordu, bu nedenle veri formatları açısından SSE’den biraz daha kısıtlayıcıydı ancak bu komut seti hala mevcuttu.
Bahsi geçen zamana kadar, derleyicilerden tutun birçok kompleks yazılım vektör matematiği için yazılımsal anlamda iyi bir desteğe sahip olmuştu. Örneğin 3.8 GHz hızında çalışan i7 2600K gibi bir işlemci, AVX komutlarıyla 230 GFLOPS (bir saniyede milyarlarca floating point/noktalı sayı işlemi) işlem yeteneğine sahip. İşlemcinin kalıp boyutu da göz önüne alındığında, bunun hiç de kötü bir değer olmadığını söyleyebiliriz.
Peki ya AVX gerçekten tam anlamıyla 3.8 GHz hızda çalışsaydı ne olurdu? Aslında AVX ne kadar kullanılıyorsa fiziksel yongaya da o kadar elektriksel yük, o kadar çok iş düşüyor. Bu nedenle ısınma çok fazla olacağından, Intel aldığı radikal kararla ısınmayı azaltmak ve güç tüketimini makul seviyeye çekmek için AVX kullanılırken saat hızını yüzde 20 kadar düşürdü. Maalesef modern bir işlemcide gelişmiş SIMD işlemleri yapmak istiyorsanız bu hız düşüşüne razı olmalısınız.
AVX ile beraber sunulan bir diğer gelişmiş yenilik ise aynı anda 3 adet değerle çalışabilmeyi sağlamasıydı. SSE’nin bütün versiyonlarında yapılan işlemler, iki değer arasında cevabın ardından yazmaçların (register) birisinin değiştirilmesiyle yapılıyordu. AVX ise SIMD işlemlerini yaparken, orijinal değerleri bozmadan sonucu ayrı bir kayıtçı (register) içinde tutuyor.
AVX2’nin Çıkışı ve FMA
2013 yılında Intel tarafından Haswell mimarisiyle piyasaya sürülen 4. Nesil Core işlemcilerde AVX2 ile beraber FMA (Fused Multiply-Accumulate) adı verilen bir birim daha eklendi. Normalde bu özelliğin AVX ile bir ilişiği olmamasına ve daha sonraki iki işlemin gerçekleşmesini sağlayan talimatı verip uygulama yeteneği skalerde çalışmasına rağmen, vektör ve matris matematiğinin kullanıldığı yerlerde de önemli ölçüde faydalı oluyordu.
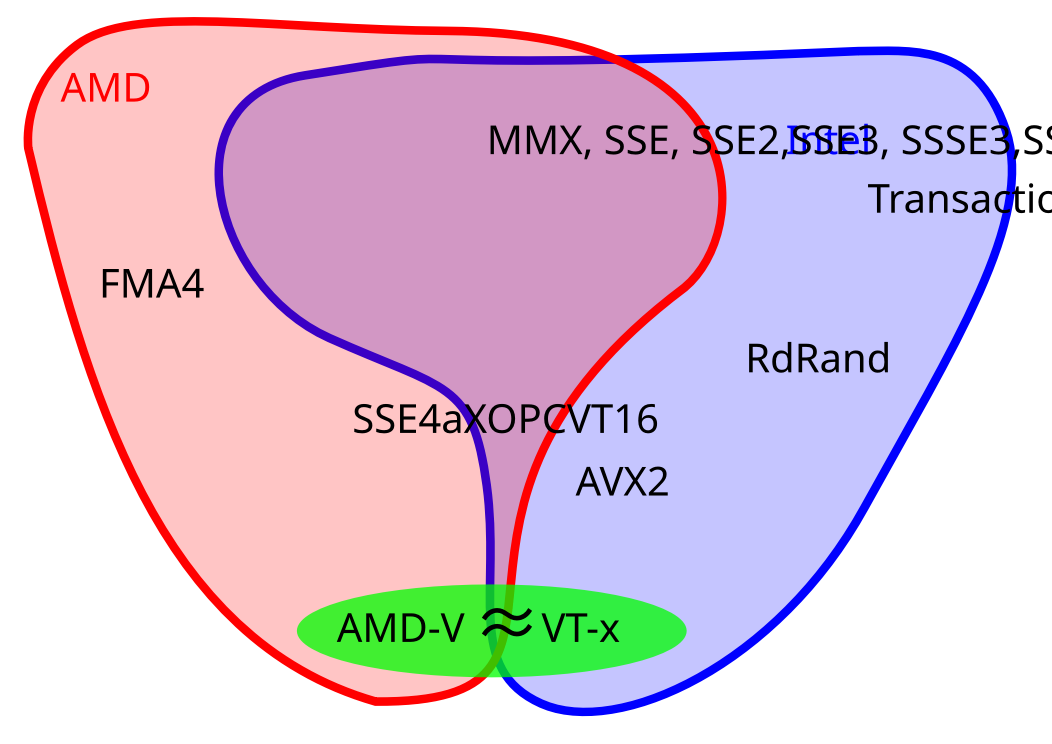
Intel tarafından piyasaya sunulan işlemcilerde kullanılan FMA uzantıları alışılagelinenin dışında bir şekilde AMD’nin FMA eklentisinden farklıydı. Hatta o kadar farklı ki, neredeyse birbirleriyle hepten uyumsuzlar. Bunun asıl sebebi olarak Intel tarafından sunulan FMA’nın 3 ayrı değerle çalışması gösterilebilir. Örneğin iki adet kaynak değer ve bir adet cevap veya üç adet kaynak değerin yerine geçen bir adet cevap şeklinde.
AMD’nin sunduğu FMA’da ise dört adet işlenen değer mevcut. Bu nedenle Intel’in FMA yapısından farklı olarak 3 adet sayı kullanarak ilgili matematiğin yapılması mümkün. Aynı zamanda cevabın da bu değerlerden biriyle değiştirilmesi gerekmiyor. FMA4 aslen matematiksel anlamda bir önceki FMA3’den çok daha iyi bir yapı olmasına rağmen, programlama anlamında ve işlemciye ilgili yapıların dahil edilmesi anlamında biraz daha zorlayıcıdır.
AVX-512
Intel, henüz AVX2 komut setinin piyasada yeni yeni boy göstermeye başladığı zamanlarda, AVX2’nin yerini almasını düşündüğü AVX-512 için hazırlanmaya başlamıştı. Asıl amaç “her şeyin daha çoğunu, çok fazlasını” sağlayabilmekti. Sadece yazmaç (register) sayısı iki kat daha artırılmayacak, boyut anlamında da iki katı daha büyüyecek ve birçok yeni komutun eklenmesinin dışında eskiye dönük destek de sağlanacaktı.
AVX-512’nin ilk kez kendini gösterdiği işlemci, Intel’in süper bilgisayarlar için geliştirdiği ikinci nesil çok çekirdekli Xeon Phi 7200 idi. Bu mükemmel işlemcinin 72 fiziksel çekirdeğe ve 288 iş parçacığına sahip olduğunu söylemeden geçmeyelim.

AVX-512’de önceki revizyonlardan daha farklı olan şey, yeni gelen vektör komut setinin 19 adet alt gruba ayrılmasıydı. Bunlar uyumluluk amacıyla oluşturulmuş olanlar, AVX-512F ve çok özel olan komutlardı. Bu ekstra komut setleri integer FMA, reciprocal (karşılıklı) matematik ve evrişimli sinir ağları oluşturma algoritmalarıyla işlem yaparken büyük ölçüde kullanılıyor.
AVX-512 ilk çıktığında Intel’in iş bilgisayarları, sunucular ve süper bilgisayarları hedefleyen en önemli kozlarından birisiydi. Fakat son çıkan 10. Nesil Ice Lake ve 11. Nesil Tiger Lake mimarili Core işlemciler de bu komut setini son kullanıcıya sunuyor. Yanlış anlamadınız, bu artık 512-bit vektör ünitesine sahip hafif bir laptop alıp kullanabileceğiniz anlamında geliyor.
AVX-512’nin Mobil Cihazlara Uygunluğu ve Dezavantajları
AVX-512 iyi bir teknoloji olduğu kadar maalesef bazı eksi yönleriyle de biliniyor. Bir merkezi işlemcide yer alan yazmaçların tümü, aşağıdaki görselde yer alan çift çekirdekli Skylake işlemcide görebileceğiniz gibi genel itibariyle “register file” adı verilen bir grup halinde bulunuyor.

Görselde sarı kutu içerisine alınan kısım vektör yazmaçlarını gösteriyor. Kırmızı kutucuk içerisindeki kısım ise tamsayı yazmacının (integer register) olası yeri. Vektör yazmacının büyüklüğü mutlaka dikkatinizi çekmiş olmalı. Görselde yer alan Skylake işlemci AVX2 için olan 256-bit yazmaçları (register) kullanıyor. Bu nedenle aynı kalıba sahip bir işlemci için AVX-512 yazmaçları bunun dört katı kadar daha (bitlerin ikiye katlanması için 2 kat, register count’un da ikiye katlanması için 2 kat) büyük olacaktır.
Sizce mobilitenin oldukça önemli olduğu dizüstü ve taşınabilir cihaz sektörü için üretilen küçük işlemcilerde, vektörler için kullanılan yazmaçların bu kadar fazla yer kaplaması iyi bir şey mi? İşlemcilerin fiziksel boyutu ve kapladığı alan söz konusu olduğunda, aslında her milimetre kare bile oldukça önemli.
Yazının başlarında da değindiğimiz gibi, vektör matematikler yapılırken AVX gibi özelliklerin kullanılması fazlasıyla ısınmaya neden olduğundan işlemcinin saat hızları otomatik olarak düşürülüyor. Bu nedenle mobil platformlar gibi taşınabilirliğin ve düşük güçle çalışmanın önemli olduğu cihazlarda AVX-512 kullanılırken çok daha fazla güce ihtiyaç duyulduğu için, AVX-512 olmayan işlemcileri barındıran mobil cihazlara nazaran ısınma daha fazla olacak. Intel mobil işlemciler AVX-512 kullanılarak bir işlem yerine getirilmeye çalışıldığında daha fazla güce ihtiyaç duyacak, daha fazla ısınacak ve daha düşük saat hızlarıyla çalışacak.
Her İşlemcideki AVX-512 Komut Seti Farklı
AVX-512’nin neden olduğu problemler maalesef ki sadece mobil işlemcilere olan etkisiyle sınırlı değil. Vektör matematiğine gerçekten ihtiyaç duyan ve sıkça kullanan yazılımların geliştiricileri, verimliliğin önemli olduğu sunucular ve iş istasyonları için ne yazık ki birden fazla sürüm geliştirmek zorunda kalacaklar. Bunun asıl nedeni bütün AVX-512 destekli işlemcilerin aynı komutlarla çalışmaması.
Örneğin IFMA seti (Integer Fused Multiply-Accumulate) sadece Tiger Lake, Ice Lake ve Cannon Lake işlemcilerde mevcut. Copper ve Cascade Lake işlemciler ise her ne kadar sunucu ve iş istasyonları için üretilmiş olsalar da bu desteği sunmamakta.
AMD tarafının ise CPU’lar için AVX-512 ile ilgilenmediğini, destek sunmayı planlamadıklarını söyleyebiliriz. Zira AMD, ekran kartı üreticisi olmanın verdiği deneyim ve görüş farklılığından olsa gerek, bu tarz büyük vektör matematiği işlemleri için GPU’ların kullanılmasının daha uygun olduğunu düşünüyor. AMD ve NVIDIA bu tarz kullanımlar için halihazırda zaten çok daha performanslı özel ekran kartları üretiyor.
Sonuç ve Geleceğe Dair Görüşler
Yıllar öncesinden günümüze kadar CPU’ların vektör matematiği yapabilme yeteneği, masaüstü bilgisayar dünyasının geleceğine yönelik atılmış en büyük adımlardan biri olarak görülüyordu. Artık işlemcilerimizin birçoğu her alanda iş görebilecek kadar yetenekli. Hemen hemen her işlemci tarafından Skaler, vektör veya matris matematiği yapılabiliyor, integer (tamsayı) ve float (ondalık/kayan noktalı) veri tipleri rahatlıkla ek komut setleri yardımıyla işlenebiliyor.
Yine de bu denklemde yıllar boyu hesap edilmeyen bir şey daha vardı. Artık CPU’ların SIMD işleme konusunda rakibi, paralel işlem yeteneğiyle öne çıkan GPU’lardı. 3 boyutlu grafik dünyasının neredeyse tamamı SIMD, vektör matematiği ve float değerlerle ilgili olduğundan, grafik hızlandırıcılar ve işlemciler de aynı şekilde fazlasıyla gelişti. Artık günümüzde 500 dolardan daha düşük bir fiyata saniyede 800 milyar SIMD talimatını rahatça gerçekleştirebilecek bir GPU edinmek mümkün. Ve bu halihazırdaki en iyi masaüstü işlemciden bile daha hızlı bir işlem kapasitesi anlamına geliyor. Her şeye rağmen GPU’ların da her türlü matematiksel işlem için değil, belirli spesifik ihtiyaçları karşılamak için geliştirildiğini unutmayın.

GPU’ların SIMD yeteneğiyle CPU’ları kıyaslayacak olursak, merkezi işlemcilerin (CPU) içerisinde yer alan komut setini biraz kullanışlı ekstra çözüm olarak düşünebilirsiniz. Ancak, grafik işlemcilerin hızla gelişmesiyle beraber, artık CPU’ların büyük oranda vektör matematiği yapmakta kullanılan birimlerden oluşması artık gerekmiyor. AMD’nin AVX2’nin halefi olacak yeni bir sürüm geliştirmemesinden de bunu anlayabiliriz.
Ayrıca ilerleyen dönemlerde belirli niş alanlar için özel mobil SoC işlemciler de görülebileceği düşünülüyor. Bütün bunlar bir yana, Intel tarafının ise kendi geliştirmiş olduğu AVX-512’yi kendi işlemcileriyle bilgisayar dünyasına sunmaya pek hevesli olduğunu görüyoruz.
Peki gelecekte AVX-1024 birimini görecek miyiz? Açıkçası buna yakın zamanda pek ihtimal vermiyoruz zira Intel büyük ihtimalle bunun yerine halihazırdaki yapıyı ek komut setleri kullanarak güncelleyip, üzerinde çalıştığı GPU hattına çok daha fazla ağırlık verecek diye düşünüyoruz.
Her şeye rağmen finalde SSE ve AVX komut setleri yazılım sektörünün vazgeçilmezi olmuş, birçok yazılımın minimum gereksinimleri arasında yer almıştır. Örneğin Adobe Photoshop minimum SSE4.2, makine öğrenimi API’si olan TensorFlow AVX, Microsoft Teams ise arka plan efektleri için AVX2 kullanıyor. Bu da bizlere gösteriyor ki GPU’lar her ne kadar bu işi daha iyi yapıyor olsalar da, CPU’lar için de vektör matematiği halen önemli. Oldukça hızlı ilerleyen teknoloji dünyasında daha nelerle karşılaşacağız, zaman içerisinde bekleyip görelim.
Sizlerin de eklemek istediği şeyler varsa yorum yazabilir, sorularınız için Technopat Sosyal‘de konu açabilirsiniz.



bunula ilgili bir youtube videosu gelse çok güzel olur oturup makale okumayı unuttuk artık :(