
Oyunlar, teknoloji, yazılımlar ve dünya hızla değişiyor. Teknoloji devleri de sürekli olarak ihtiyaçlara yanıt verebilmek, gidişata yön vermek, büyümek amacıyla büyük yatırımlar yapıyor, yeni mimariler üzerinde çalışıyor. Başlamadan not düşelim, grafik çipleri yalnızca oyunlar konusunda önemli değil: Yüksek hesaplama gerektiren yapay zeka, büyük araştırma projeleri, fotoğraf-video yazılımları ve daha birçok alanda kritik rol oynuyor. Şu anda piyasada AMD, NVIDIA ve Intel olmak üzere üç büyük oyuncu var. Biz de devlerin mevcuttaki en güncel mimarilerine daha yakından bakacağız: Ada Lovelace, RDNA 3 ve Alchemist.
Evet, masada artık Intel de var. NVIDIA yıllardır harici GPU pazarında tartışmasız liderliğini sürdürürken sürekli üzerine koymaya devam ediyor. Sektör lideriyle rekabet etmek için sıkı çalışan, hem donanım hem de yazılım açısından yenilikler sunan AMD ise kendini çok geliştirdi. Uzun zamandır arenayı iki şirket paylaşıyordu. Intel, Alchemist ile oyuna dahil olurken gelecek için umut verici projeler üzerinde çalıştıklarını söylüyorlar.
Çoğu kişi işin iç detayını bilmez, bilmek de istemez. Kullanıcılar yeni bir ekran kartı (veya harici GPU’ya sahip dizüstü bilgisayar) alırken yüzeysel araştırmalar yapıp bir karar verir. Üreticiler yeni duyurular yaptığında mümkün oldukça tüm teknik detayları sizlerle paylaşmaya çalışıyoruz. Şimdi ise hem mevcut bilgilerimiz hem de farklı kaynaklardan elde ettiğimiz bilgilerle birlikte daha derinlere ineceğiz.
GPU’ların Yapısı
Baştan belirtelim, her mimarinin kendine has bir tasarımı vardır. Teknik sayfalarda çekirdek sayıları, ışın izleme birimleri, hesaplama üniteleri ve bellek boyutu gibi birçok detay görürsünüz. Ancak şirketten şirkete, hatta mimariden mimariye çok şey değiyor. Şöyle başlayalım: İki ayrı ekran kartı arasında kıyaslama yaparken çekirdek sayılarına bakarak bir karar veremezsiniz.
AMD, Intel ve NVIDIA gibi şirketler grafik yongalarını tasarlarken tamamen farklı yaklaşımlar benimsemekte. Ayrıca hedef kitleye ve ürün sınıfına göre mimarilerde değişiklikler olabiliyor. Örneğin AMD, üst segment ekran kartları için Navi 31 GPU silikonunu kullanıyor. Bu grafik yongası üst düzey performans isteyenlerin tercih ettiği Radeon RX 7900 serisinde kullanıldı.

Rakip yeşilliler, AD102 grafik çipini premium pazara yönelik olan RTX 4090 serisi için tasarladı. Bu kartların mevcutta bir rakibi yok zira RX 7900 ekran kartları RTX 4080 serisiyle rekabet edebiliyor. Intel’in mevcuttaki en büyük ve güçlü GPU’su ACM-G10 adını taşıyor. Ancak mavi takım pazarda henüz yeni; RTX 3060/RX 6600 gibi ürünlerle rekabet edebiliyorlar.
AMD Navi 31
AMD, Navi x1 (Navi 31, Navi 21 gibi) grubundaki grafik işlemcilerine genelde üst segment ekran kartlarında yer verir. Navi x2 (Navi 32, Navi 22 gibi) daha alt grubuna hitap ederken Navi x3 de aynı şekilde aşağıya doğru iniyor.
Navi 31, önceki nesil Radeon RX 6000 serisinde kullanılan Navi 21 silikonuna göre önemli farklılıklarla birlikte geliyor. Gölgelendirici Motorları (Shader Engine-SE) artık daha az sayıda (20 değil, 16) Hesaplama Birimi (Compute Unit-CU) barındırıyor, ancak şimdi toplamda 60 SE mevcut. Bu da Navi 31’in toplam 6144 Akış İşlemcisi (Stream Processor-SP), yani 96 CU’ya ulaşabileceği anlamına geliyor. AMD ayrıca farklı mimari değişiklikler de yaptı, bunlara detaylıca değineceğiz.

Her Gölgelendirici Motoru ayrıca rasterleştirmeyi gerçekleştirmek için özel bir birim, üçgen kurulumu için ilkel bir motor, 32 işleme çıktı birimi (ROP) ve iki adet 256kB L1 önbellek içeriyor. Önbellek miktarı iki kat büyüse de SE başına ROP sayısı aynı kaldı.
AMD, rasterizasyonu ve ilkel motorları çok fazla değiştirmedi. Belirtilen %50’lik iyileştirmeler, Navi 21 çipinden %50 daha fazla SE’ye sahip olduğundan dolayı silikon geneli için. Bununla birlikte, SE’lerin talimatları işleme biçiminde, birden fazla çizim komutunun daha hızlı işlenmesi ve işlem hattı aşamalarının daha iyi yönetilmesi gibi değişiklikler var; bu da bir CU’nun başka bir göreve geçmeden önce bekleme süresini azaltmakta.
Birazdan tüm detayları ele alacağız lakin asıl önemli değişiklikten bahsetmedik. AMD, RDNA 3 mimarisiyle çok yongalı tasarıma (çiplet tasarım) geçiş yaptı.
Intel ACM-G10
Uzun zamandır sızıntılarda DG2-512 adıyla bilinen GPU, ACM-G10 adıyla ekran kartlarında yerini almaya başlamıştı. Intel veri merkezlerine yönelik daha büyük grafik çipleri üretiyor üretmesine, ancak son tüketicilerin eline geçen en büyük GPU ACM-G10.
Blok diyagramı oldukça standart bir düzene sahip olsa da AMD’ninkinden çok NVIDIA’nın tasarımına benziyor. Her biri 4 adet Xe-Core (Xe-Çekirdeği) içeren 8 Render Slice (İşleme Dilimi/Bölümü) ile birlikte toplam 512 Vector Engine (Vektör Motoru) ortaya çıkıyor. Ayrıca bunlar MXM Motoru olarak da adlandırılmakta. Her bir Vektör Motorunda 8 GPU Çekirdeği (Gölgelendirici) bulunuyor ve toplamda 4096 rakamına ulaşıyoruz.

Her bir Render Slice içinde bir ilkel birim, rasterleştirici, derinlik tampon işlemcisi, 32 doku birimi ve 16 ROP bulunuyor. Bununla birlikte, AMD’nin RNDA 3 çipi her biri 128 ALU’ya sahip 96 Hesaplama Birimi barındırırken, ACM-G10’da çekirdek başına 128 ALU’ya sahip toplam 32 Xe Çekirdeği mevcut. Yani yalnızca ALU sayısı açısından bakıldığında, Intel’in Alchemist destekli GPU’su AMD’ninkinin üçte biri büyüklüğünde.
NVIDIA AD102
Ada Lovelace mimarisini kullanan AD GPU’lara ve amiral gemisi AD102’ye gelelim. Önceki nesil Ampere mimarili GA102 ile aralarında radikal farklar bulunmuyor, ancak yeni GPU çok daha büyük. Ayrıca farklı detaylar da var.
NVIDIA, 6 Doku İşleme Kümesi (Texture Processing Cluster-TPC) içeren Grafik İşleme Kümeleriyle (Graphics Processing Cluster-GPC) tasarım sürecine devam ediyor. Bunların her biri Çoklu Akış İşlemcisi (Streaming Multiprocessor-SM) barındırıyor. Yapılandırma Ada Lovelace ile değişmese de toplam rakamlarda değişiklik oldu.

Kırpılmamış AD102 grafik kalıbında GPC sayısı 7’den 12’ye çıktı. Böylelikle toplam 144 SM ve 18.432 CUDA çekirdeğine sahip bir GPU inşa etmek mümkün hale geldi. Navi 31’in 6144 SP’si ile kıyaslandığında 18.432 devasa bir rakam gibi görünebilir lakin dediğimiz gibi tasarım çok farklı.
Bir not olarak, SM’lerin AMD tarafındaki CU ile benzer konumda olduğunu ekleyelim. Ayrıca her ikisi de 128 ALU içeriyor. Yani Navi 31, Intel ACM-G10’un iki katı büyüklüğündeyken (yalnızca ALU sayısı açısından) AD102 3.5 kat daha büyük.
Uzun lafın kısası, teknik rakamlar ve ölçeklendirme açısından bazı benzerlikler olsa da her şey temelde tamamen farklı. Bu nedenle çekirdek sayılarıyla doğrudan performans kıyaslaması yapmak mümkün değil. Ancak kıyaslama yapılabilecek bir şey var: Üç işlemcinin tekrardan kullanılan en küçük entegre parçaları.
En Temel Birim: Çekirdekler (Gölgelendirici)
Tüm işlemciye genel bakıştan sonra şimdi çiplerin kalbine inelim. Gölgelendirici olarak da bilinen çekirdekler en küçük GPU birimleridir. Şirketler çiplerini tanımlarken, özellikle de genel diyagramlar söz konusu olduğunda farklı terimler ve ifadeler kullanıyor. Biz de işleri biraz basitleştirmeye çalışacağız.
AMD’de Büyük Değişim: RDNA 3 Mimarisi
İnce Detaylar
AMD’nin GPU’nun gölgelendirme bölümündeki en küçük birleşik yapısı Çift İşlem Birimi (Double Compute Unit-DCU) olarak adlandırılmakta. Bazı yerlerde ise Çalışma Grubu İşlemcisi (Workgroup Processor-WGP) anılıyor.
Birçok yönden genel düzen ve yapısal unsurlar RDNA 2’ye oldukça benzer. İki Hesaplama Birimi bazı önbellekleri ve belleği paylaşıyor, her biri 32 Akış İşlemcisinden (SP) oluşan iki set içeriyor.
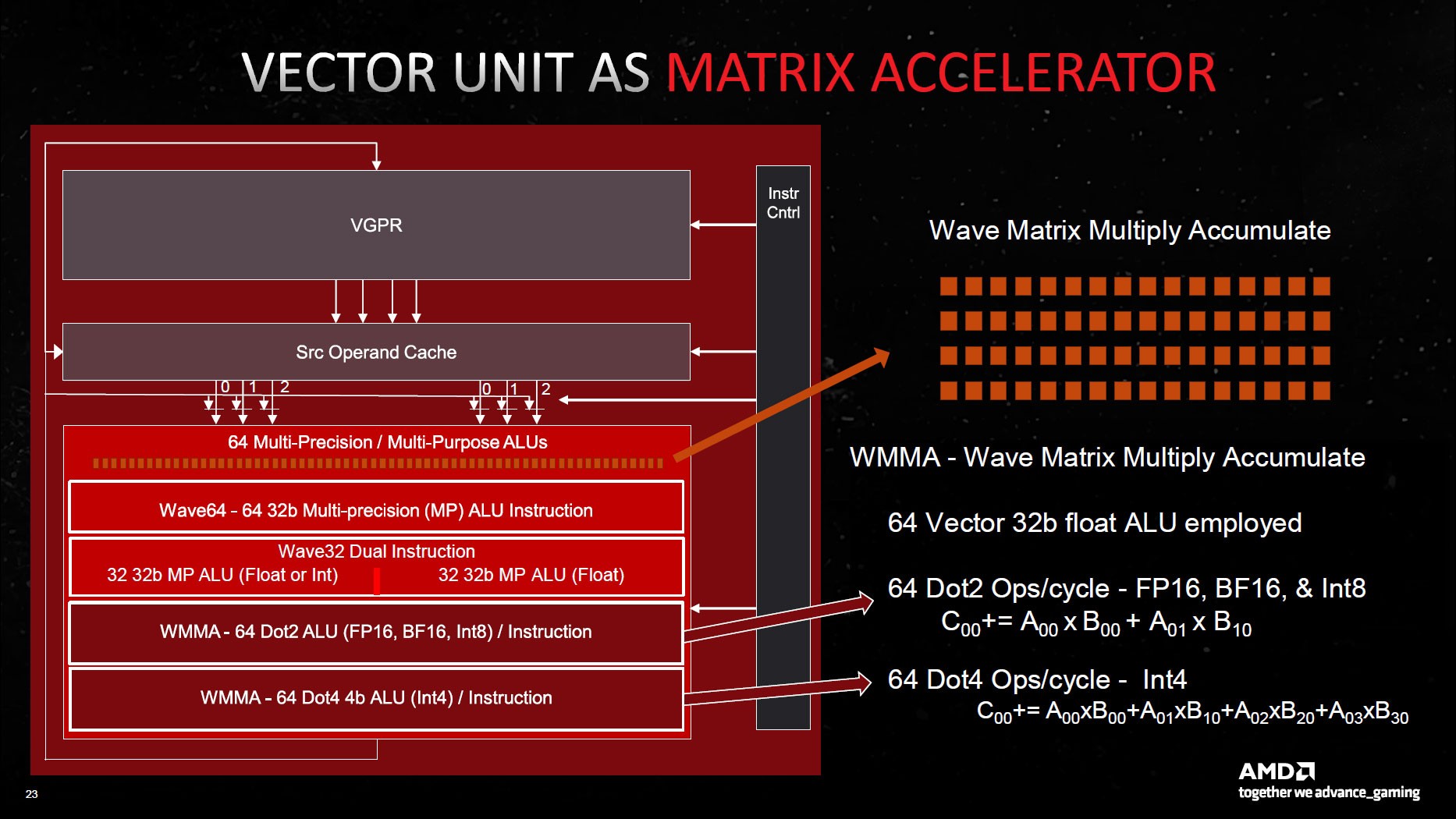
RDNA 3 ile değişen şeye gelince, her SP artık iki kat daha fazla aritmetik mantık birimi (ALU) barındırıyor. Artık CU başına iki SIMD64 birimi bankası ve her bankanın iki veri portu var; biri kayan nokta, tamsayı ve matris işlemleri için, diğeri ise sadece kayan nokta ve matris için.

AMD farklı veri formatları için ayrı SP’ler kullanıyor. RDNA 3 grafik yongalarında konumlandırılan Hesaplama Birimleri FP16, BF16, FP32, FP64, INT4, INT8, INT16 ve INT32 formatlarını desteklemekte.
SIMD64 kullanımı, her bir iş parçacığı zamanlayıcısının saat döngüsü başına 64 iş parçacığından oluşan bir grup (dalga cephesi olarak adlandırılır) gönderebileceği veya 32 iş parçacığından oluşan iki dalga cephesini birlikte gönderebileceği anlamına geliyor. AMD, önceki RDNA mimarilerindeki aynı talimat kurallarını korudu; dolayısıyla bu, GPU/sürücüler tarafından kontrol edilen bir unsur.
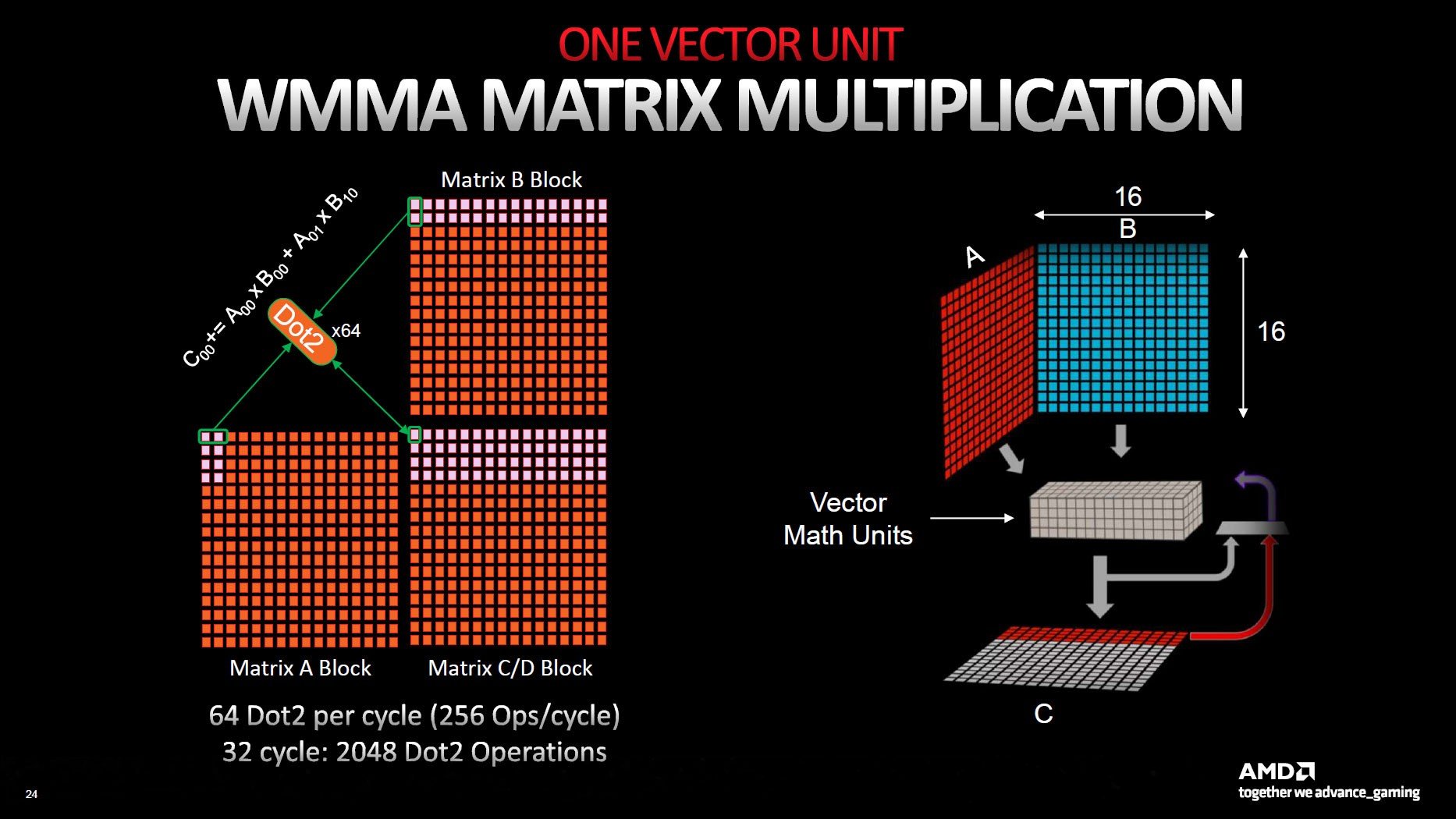
Bir diğer önemli yenilik ise AI Matrix Hızlandırıcı (AI Matrix Accelerator) olarak isimlendirilen özel birimler. Intel ve NVIDIA mimarlierinin aksine, bunlar ayrı birimler olarak hareket etmiyor. Tüm matris işlemleri SIMD birimlerini kullanıyor ve bu tür hesaplamalar (Wave Matrix Multiply Accumulate, WMMA olarak adlandırılıyor) 64 ALU’nun tamamını kullanmakta.
Ham işlem gücünden emin değiliz, ancak AI hızlandırıcıların hem INT8 hem de BF16 (brain-float 16-bit) işlemlerini desteklediğini biliyoruz. Yani muhtemelen NVIDIA’nın Tensor çekirdeklerine benzer bir yapı var, ancak desteklenen toplam komut seti sayısı aynı değil. Ne olursa olsun, AMD yeni yapay zeka hızlandırıcılarının 2.7 kata kadar iyileştirme sağladığını iddia ediyor. Hızlandırıcı sayısının artması, daha fazla Hesaplama Ünitesi ve artan verimlilik bir araya gelerek bu performans artışını sağlıyor.
RDNA 2 ile karşılaştırıldığında değişiklikler nispeten küçük. Eski mimari 64 iş parçacığı dalga cephesini (wavefront-Wave64 olarak da biliniyor) de işleyebiliyordu, ancak bunlar iki döngü boyunca veriliyordu ve her Hesaplama Biriminde her iki SIMD32 bloğunu da kullanıyordu. Şimdi ise tüm bunlar tek bir döngüde yapılabiliyor ve yalnızca bir SIMD bloğu kullanılıyor.
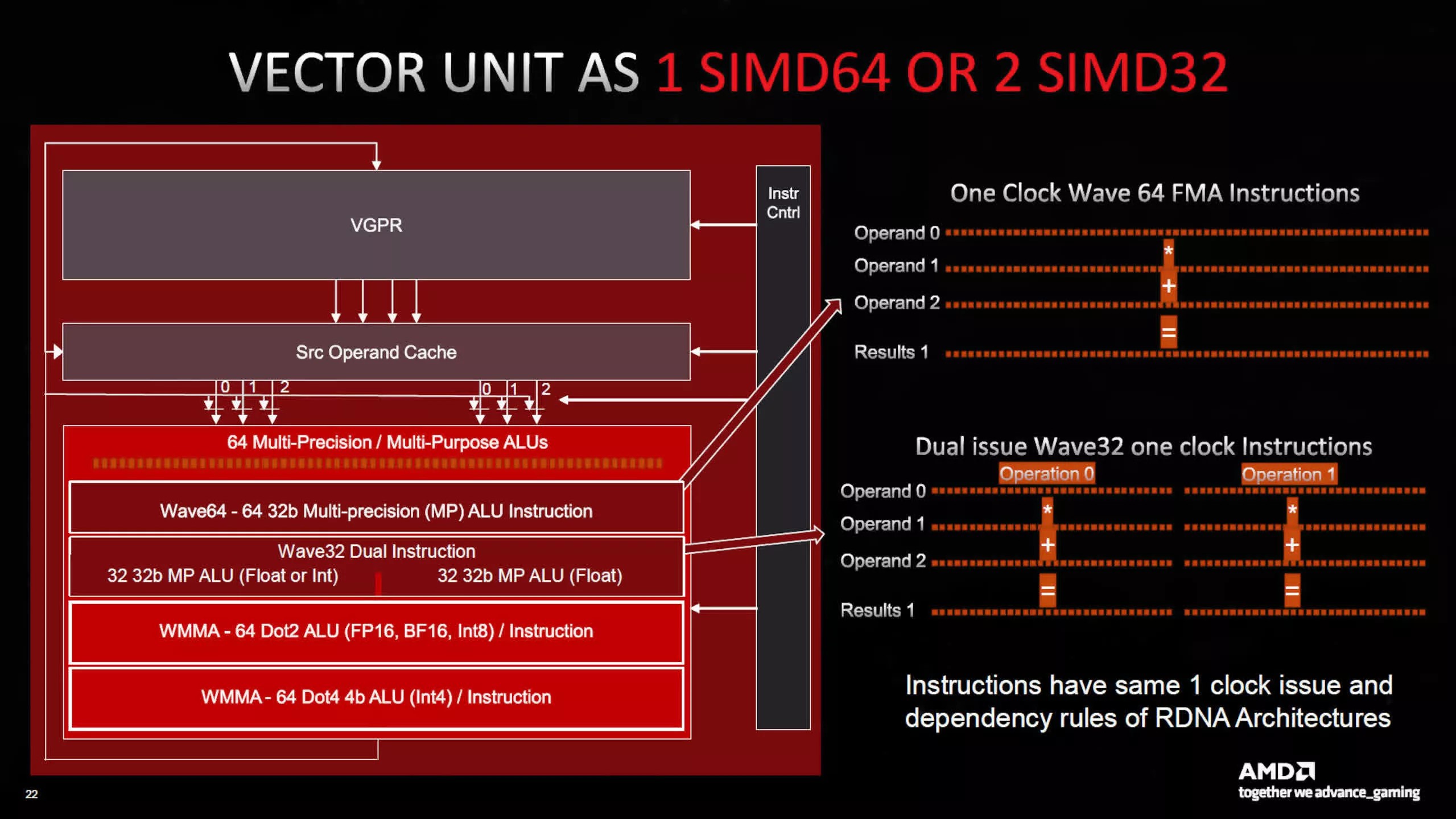
Önceki belgelerde AMD, Wave32’nin genellikle hesaplama ve tepe noktası gölgelendiricileri (ve muhtemelen ışın gölgelendiricileri de) için kullanıldığını, Wave 64’ün ise çoğunlukla piksel gölgelendiricileri için kullanıldığını ve sürücülerin gölgelendiricileri buna göre derlediğini belirtmişti. Dolayısıyla, tek döngülü Wave64 komut tipine geçişle birlikte büyük ölçüde piksel gölgelendiricilere bağımlı olan oyunlara bir destek sağlanmakta.
Diğer yandan, tüm ekstra güçten tam olarak faydalanmak için her şeyin doğru şekilde yürütülmesi gerekiyor. AMD, ALU’ları iki katına çıkardığı için yazılımcıların komut düzeyinde paralelliği mümkün olduğunca çok kullanması gerekiyor. Bu grafik dünyasında yeni bir şey değil, ancak RDNA’nın eski GCN mimarisine göre sahip olduğu önemli bir avantaj, tam kullanıma ulaşmak için çok fazla iş parçacığına ihtiyaç duymamasıydı. Modern render işlemlerinin oyunlarda ne kadar karmaşık hale geldiği göz önüne alındığında, geliştiricilerin shader kodlarını yazarken ellerinde biraz daha fazla iş olacak.
Mimari Özellikler
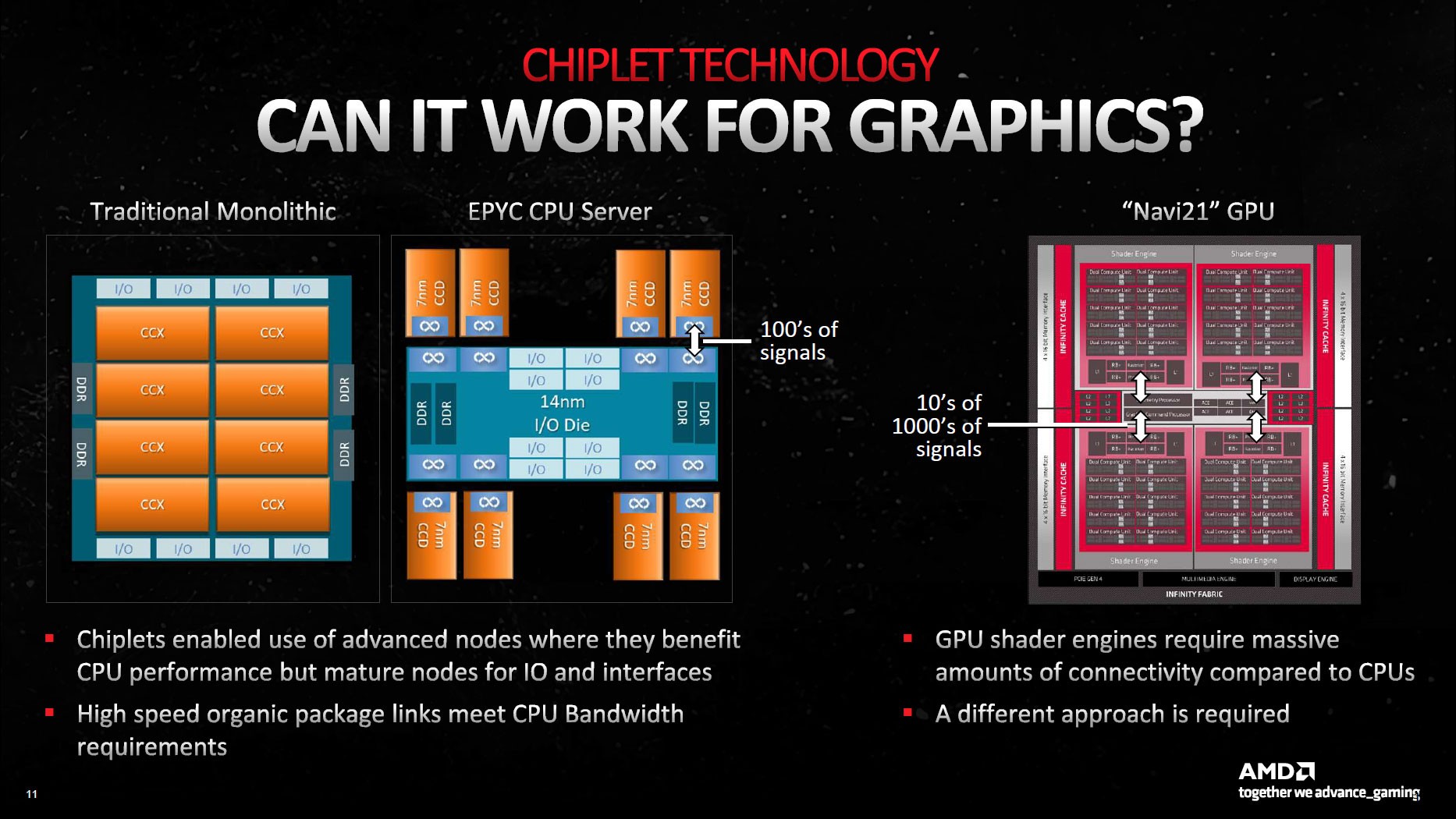
Daha önce birçok kez belirttiğimiz gibi, RX 7900 serisinde Navi 31 isimli üst sınıf bir GPU kullanılıyor. Navi 31, Grafik İşlem Kalıbı (GCD) ve Bellek Önbellek Kalıbı (MCD-Memory Cache Dies) olmak üzere iki temel parçadan meydana geliyor. AMD’nin Zen 2/3/4 işlemcilerinde benimsenen çiplet tasarımla benzerlikler var, ancak her şey grafik dünyasının ihtiyaçlarına uyacak şekilde tasarlanmış. Başka bir deyişle, kırmızı takım işlemci tarafındaki deneyimlerini grafik cephesine aktarmayı başarmış.
AMD Zen Mimarisinin Temeli
AMD, Zen 2 ve sonrasındaki işlemcilerde sistem belleğine bağlanan ve PCIe Express arayüzü, USB bağlantı noktaları ve entegre grafik işlemcisi (Zen 4 ile geldi) gibi birimleri barındıran bir Giriş/Çıkış Kalıbı (IOD) kullanıyor. İçerisinde birçok ayrı birim barındıran bu yonga, AMD’nin Infinity Fabric teknolojisiyle bir veya birden fazla CCD’ye (Core Compute Die veya Core Complex Die) bağlanıyor. Bu CCD’ler ise CPU çekirdeklerini, önbellek birimini ve farklı bileşenleri içeriyor.
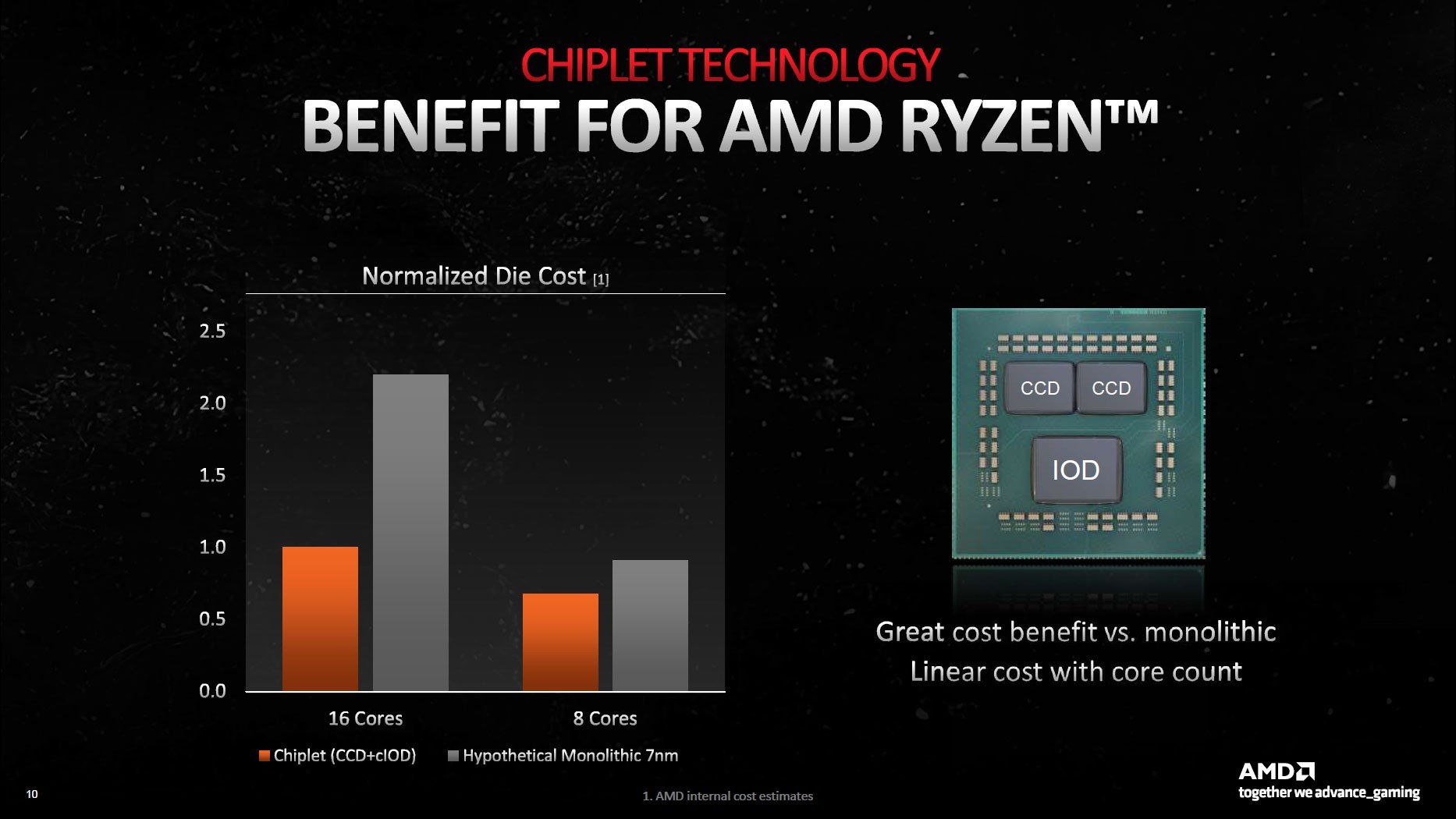
Çekirdekleri içinde barındıran birimler küçük yapıdayken, IOD yaklaşık 125 mm² (Ryzen 3000) ile 416 125 mm² (EPYC xxx2 nesil) arasında değişkenlik gösterebiliyor. En son teknolojileri barındıran Zen 4 mimarisinde işler biraz daha değişti. Ryzen 7000 işlemcilerde CCD’ler TSMC N5 (5nm), IOD TSMC N6 (6nm) teknolojisine dayanıyor. Yani böyle yapılarda ihtiyaca ve maliyetlere göre kullanılan teknolojiler farklılık gösterebiliyor. Bu da aslında üreticiler için önemli bir avantaj.
RDNA 3 Mimarisine Derinlemesine Dalış
Şimdi gelelim asıl konumuza. GPU’lar bildiğiniz gibi farklı gereksinimlere sahip ve çok farklı yapıda. Grafik işlem birimleri, tüm GPU çekirdeklerini beslemek için bol miktarda bellek bant genişliğine ihtiyaç duyar. Örneğin, 12 kanallı DDR5 yapılandırmasına sahip devasa EPYC 9654 bile ‘yalnızca’ 460,8 GB/s’ye kadar bant genişliği sunuyor. RTX 4090 ve RTX 3090 Ti gibi ekran kartları ise bu miktarları ikiye katlarken 1 TB/sn seviyesinde bant genişliğine sahip.

GPU yongalarının etkili bir şekilde çalışması için AMD’nin farklı bir şey yapması gerekiyordu. Şirket mühendisleri çözümü CPU yapılandırmasının tam tersini uygulamakta buldu: ana işlem merkezi olarak GCD kullanılırken, bellek kontrolcüleri ve önbellek birden fazla küçük yongaya yerleştirildi.
GCD adı verilen birim video kodlama donanımı, ekran arayüzleri ve PCIe bağlantısı gibi diğer temel işlevlerle birlikte Bilgi İşlem Birimlerini (Compute Unit olarak biliniyor) içinde barındırıyor. Navi 31 GCD, tipik grafik işleme görevlerini üstlenmek üzere 96 adede kadar CU barındırabiliyor. AMD, GCD’yi gelişmiş Infinity Fabric teknolojileriyle çipin etrafına yayılan MCD’lere ve kartın geri kalanına bağlıyor.
Adından da anlaşılacağı gibi, MCD’ler (bellek kalıpları) büyük L3 önbellek bloklarını (Infinity Cache) ve fiziksel GDDR6 bellek arayüzünü içeriyor. Bununla birlikte, MCD’lerin GCD’ye bakan tarafında Infinity Fabric bağlantıları yer alıyor.
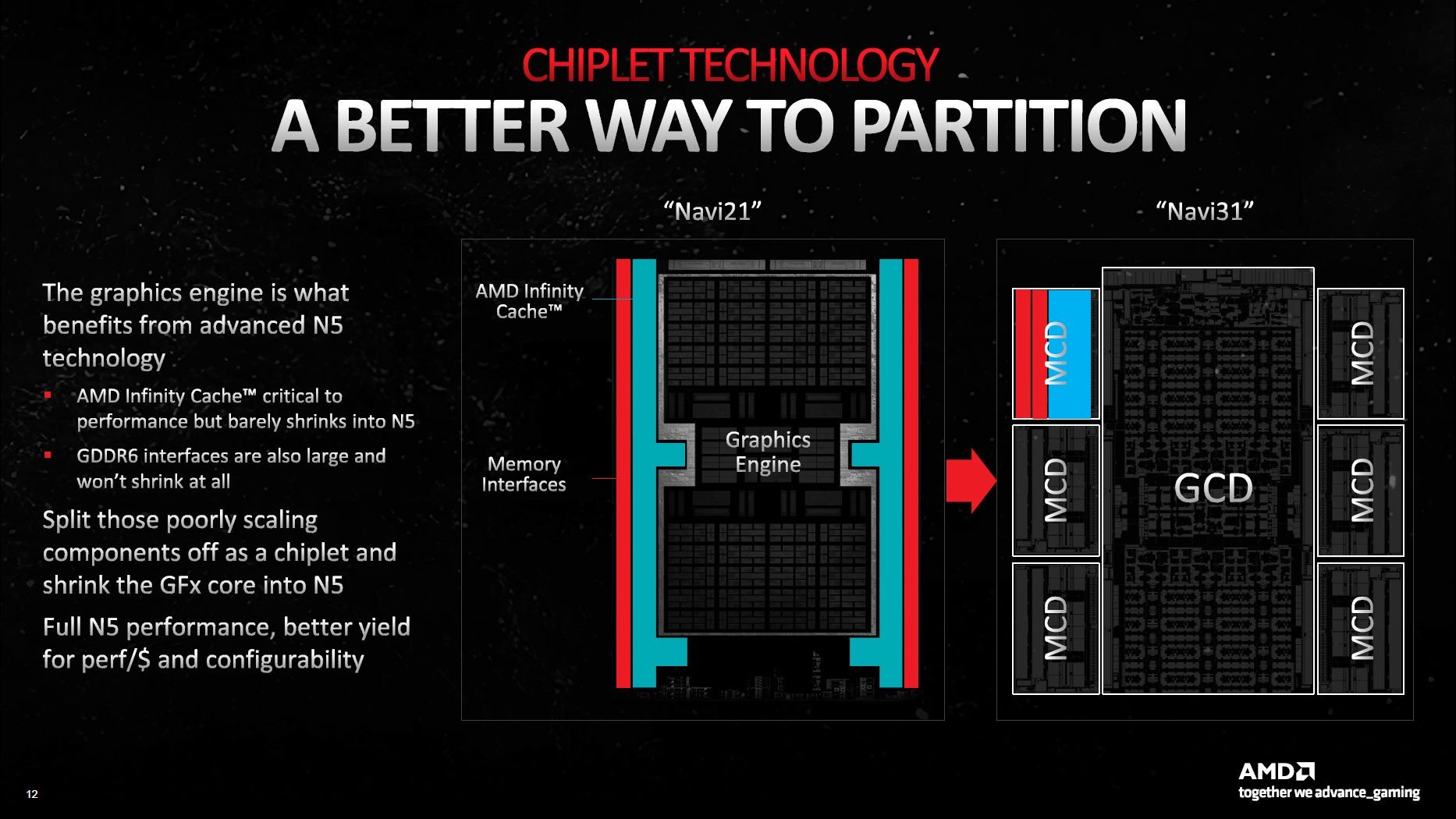
AMD, TSMC’nin N5 teknolojisini kullanarak 300 mm² boyutundaki Navi 31 GCD’ye 45.7 milyar transistör entegre etmeyi başardı. TSMC N6 bandından çıkan 37 mm² boyutundaki MCD’lerde ise 2.05 milyar transistör bulunmakta.
Yüksek Performanslı Ara Bağlantı Teknolojileri: Fanout
Çipler arası ara bağlantı teknolojileri söz konusu olduğunda birçok endişe ortaya çıkar. Bu noktada ilk olarak Infinity Fabric bağlantılarının gerektirdiği güç (harici çipler neredeyse her zaman daha fazla güç kullanır) akıllara geliyor. Bunun yanında, bağlantı teknolojisinin verimliliği ve hızı çok önemlidir.



Sonuç olarak ortaya “Fanout” ara bağlantısı olarak adlandırılan bir çözüm çıktı. Slaytlar her şeyi kapsamlı şekilde açıklamıyor, ancak sunum görsellerinde CPU’lar (CPU chiplet bandwidth) ve GPU’larda (MCD bandwidth) sunulan bant genişliğinin farkını görebilirsiniz.

İşlemcilerde 25 ara bağlantı bulunurken, GPU’lar için kullanılan 50 ara bağlantı daha küçük bir alana yerleştiriliyor. Bu da güç gereksinimlerini önemli ölçüde azaltıyor. AMD, tüm Infinity Fanout bağlantıları toplamda 3,5 TB/s etkin bant genişliği sağlarken toplam GPU güç tüketiminin yalnızca %5’inden azını oluşturduğunu söylüyor.
| Bit başına pikojul (pJ/b) | |
|---|---|
| On-die | 0.1 |
| Foveros | 0.2 |
| EMIB | 0.3 |
| UCIe | 0.25-0.5 |
| Infinity Fabric (Navi 31) | 0.4 |
| TSMC CoWoS | 0.56 |
| Bunch of Wires (BoW) | 0.5-0.7 |
| Infinity Fabric (Zen 4) | ? |
| NVLink-C2C | 1.3 |
| Infinity Fabric (Zen 3) | 1.5 (?) |
Burada ilginç bir nokta var: hem GCD hem de MCD’lerdeki Infinity Fabric mantığı yongalarda büyük bir alan kaplıyor. GCD’deki altı Infinity Fabric arayüzü kalıp alanının yaklaşık %9’unu kullanırken, arayüzler MCD’lerdeki toplam kalıp boyutunun yaklaşık %15’ini oluşturuyor.

Infinity Fabric arayüzünü ortadan kaldırıp çipi tek bir parça halinde TSMC 5nm teknolojiyle inşa etselerdi, GPU boyutu muhtemelen 400-425 mm² ölçülerinde olacaktı. TSMC N5’in maliyeti TSMC N6’dan çok daha yüksek olacak ki AMD çok yongalı tasarıma geçiş yapmayı göze almış.
Hesaplama Birimleri (CU)
Çiplet tasarımı bir kenara, en önemli değişiklikler Hesaplama Birimleri (Compute Unit-CU) ve Çalışma Grubu İşlemcileri (Workgroup Processor-WGP) tarafında gerçekleştirildi. Bunlar arasında L0/L1/L2 önbellek boyutlarında güncellemeler, FP32 ve matris iş yükleri için daha fazla SIMD32 kaydı ve bazı öğeler arasında daha geniş ve daha hızlı arayüzler yer alıyor.
RDNA 3, RDNA yongaların ana yapı taşı haline gelen Hesaplama Birimleri açısından önemli (çiftli işlem birimleri) geliştirmelerle geliyor. Görsellerde RDNA 3 ve RDNA 2 pek farklı görünmeyebilir, ancak zamanlayıcı ve Vektör GPR’leri için ilk blokta “Float / INT / Matrix SIMD32” ve ardından “Float / Matrix SIMD32” ibarelerini görebilirsiniz. Bu ikinci blok RDNA 3 mimarisinde yeni ve temel olarak kayan nokta veriminin iki katına çıkarılması anlamına gelmekte.


Resmiyette her bir Hesaplama Ünitesi’nde 64 Akış İşlemcisi (Stream Processor) yer alıyor. Her şey RDNA 2 mimarisiyle aynı görünebilir, ancak yeni yapılandırma sayesinde aslında toplam 12.288 ALU (Aritmetik Mantık Birimleri-gölgelendirici) elde ediyoruz.
Yeni RDNA 3 birleşik Hesaplama Birimi’nde 64 adet çift çıkışlı (dual-issue) Akış İşlemcisi (GPU gölgelendiricileri) bulunuyor. Bu RDNA 2 mimarisine kıyasla iki katlık bir fark demek. AMD, her SIMD birimine farklı iş yükleri gönderebiliyor veya her ikisinin de aynı komut türü üzerinde çalışmasını sağlayabiliyor.
Aslında bu konu herkeste kafa karışıklığı yaratmıştı. Bazı yerlerde Navi 31’in 6.144, bazı yerlerde ise 12.288 gölgelendiriciye sahip olduğu söyleniyordu. Baş GPU mimarı ve RDNA 3 tasarımının arkasındaki ana isim olan Mike Mantor, bu konu sorulduğunda 12.288 rakamını verdi. Ancak AMD sunumlarında düşük rakamları kullanmayı seçiyor.
Önbellek ve Ara Bağlantı
Önbellekler ve sistemin geri kalanı arasındaki arabirimleri tümünde geliştirmeler yapıldı. Örneğin L0 önbellek 32 KB’a (RDNA 2’nin iki katı), L2 önbellek 6 MB’a (RDNA 2’den 1.5 kat daha büyük) ve L2 önbellek yine 6 MB’a (1.5 kat) yükseltildi. Ek olarak, ana işlem birimleri ile L1 önbellek arasındaki bağlantı artık 1ç5 kat daha geniş ve saat başına 6144 bayt verim sağlıyor. Aynı şekilde, L1 ve L2 önbellek arasındaki bağlantı da 1.5 kat daha geniş (saat başına 3072 bayt).
Infinity Cache olarak da adlandırılan L3 önbellek Navi 21’e göre (96 MB’a karşı 128 MB) küçüldü. Buna karşılık L3’ten L2’ye bağlantı artık 2.25 kat daha geniş (saat başına 2304 bayt) ve toplam aktarım hızı çok daha yüksek.
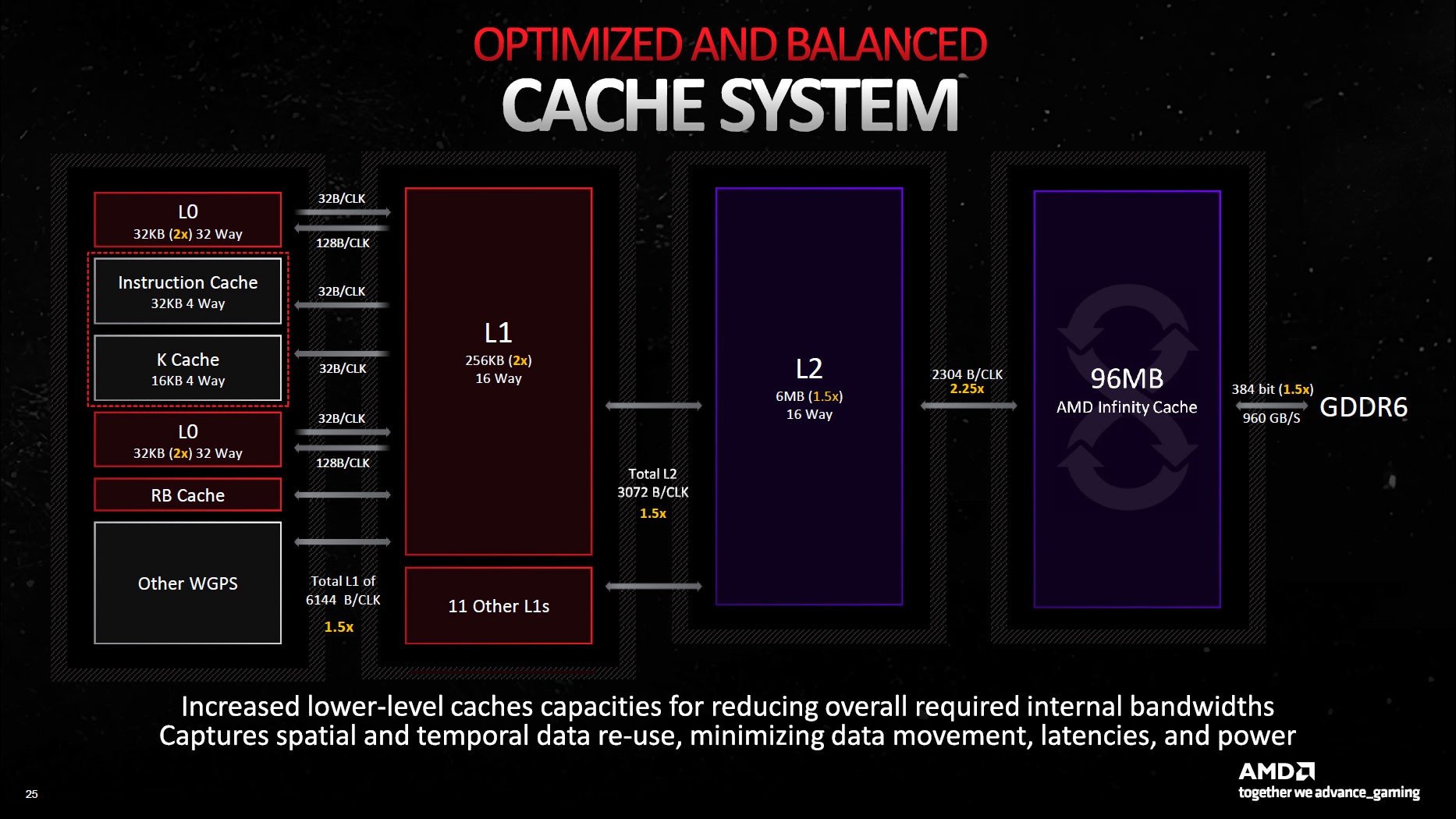
Son olarak, GDDR6 bellek yapılandırmasında toplam 384 bit bağlantı için artık 6 adede kadar 64 bit GDDR6 arabirimi var. VRAM toplam 960 GB/sn’lik bant genişliğini ortaya çıkarırken 20 Gbps (RX 6×50 kartlarda 18 Gbps ve orijinal RDNA 2 yongalarında 16 Gbps) hızında çalışıyor.
Başka bir noktaya parmak basacak olursak, GDDR6 ve GDDR6X arasındaki fark da yeni nesille birlikte daraldı. 960 GB/sn bant genişliği sunan RX 7900 XTX, 1008 GB/sn bant genişliğine sahip RTX 4090’a çok yakın. RTX 3090 (936 GB/sn) ve RX 6900 XT’nin (512 GB/sn) arasındaki fark ise çok daha fazlaydı.
2. Nesil Ray Tracing (Işın İzleme)
Işın Hızlandırıcı (Ray Accelerator) birimleri ikinci nesle geçiş yapıyor. Bu birimlerin sayısı aynı kalmış. Yani tıpkı RDNA 2 mimarisinde olduğu gibi, her İşlem Birimi’nde (Compute Unit) birer Ray Accelerator yer alıyor.

Kırmızı takım, çekirdeklerin ışın izleme senaryolarında 1.5 kat daha fazla ışın üretebilecek kapasiteye ulaştığını belirtiyor. Ayrıca GPU’ya ışın izlemeyle ilgili yeni komut setleri de eklenmiş. Her bir CU’da bir RA olduğunu söylemiştik. AMD’ye göre bu birimler eskisine göre %50 daha performanslı.
Intel’in İlk Göz Ağrısı: Alchemist (Xe-HPG) Mimarisi
Mavi takımla devam edelim. Xe-Core olarak isimlendirilen birimler AMD tarafında DCU ile, yani WGP’ler ile eşdeğer. Bu GPU birimleri ilk bakışta AMD’nin tasarımına kıyasla devasa görünüyor.
RDNA 3’teki tek bir DCU dört SIMD64 bloğu barındırırken, Alchemist’teki Xe-Core’ların her biri kendi iş parçacığı zamanlayıcısı ve gönderim sistemi tarafından yönetilen 16 SIMD8 birimi içermekte. AMD’nin Akış İşlemcileri gibi, Alchemist’teki Vektör Motorları da tamsayı ve kayan veri formatlarını işleyebiliyor. FP64 desteği yok, ancak bu oyunlarda pek sorun teşkil etmiyor.
AMD RDNA 3 ve NVIDIA Ada Lovelace mimarileri tek bir döngüde 64 veya 32 iş parçacığı çıkarabilen işlem bloklarına sahipken, Intel’in mimarisi bir Vektör Motorunda aynı sonucu elde etmek için 4 döngü gerektiriyor – bu nedenle Xe-Core başına 16 SIMD birimi var.
Bu da oyunlar Vektör Motorlarının tamamen dolu olmasını sağlayacak şekilde kodlanmazsa SIMD’lerin ve ilgili kaynakların (önbellek, bant genişliği vb.) boşta kalacağı anlamına geliyor. Intel, Arc ekran kartı sunumlarında kıyaslama sonuçlarını paylaşırken ortak bir temayı baz alıyor: Daha yüksek çözünürlüklerde ve/veya çok sayıda karmaşık, modern gölgelendirici rutini içeren oyunlarda daha iyi performans.
Bunun nedeni kısmen yüksek düzeyde birim alt bölümü ve kaynak paylaşımının gerçekleşmesi. Chips and Cheese web sitesi tarafından yapılan mikro-benchmarking analizi, tüm ALU zenginliğine rağmen mimarinin uygun kullanımı elde etmekte zorlandığını göstermekte.
Xe Çekirdekleriyle ilgili diğer hususlara geçecek olursak, “Level 0” komut önbelleğinin ne kadar büyük olduğu belli değil. Ancak AMD tarafında 4 yönlü olduğu durumda (çünkü dört SIMD bloğuna hizmet ediyor) Intel tasarımının 16 yönlü olması gerekiyor, bu da önbellek sisteminin karmaşıklığını artırıyor.

Intel ayrıca işlemciye matris işlemleri için her Vektör Motoru için bir tane olmak üzere özel birimler kullanmayı tercih etmiş. Bu kadar çok sayıda birim, yonga kalıbının önemli bir kısmının matris matematiğini işlemeye ayrıldığı anlamına geliyor.
AMD bunu yapmak için DCU’nun SIMD birimlerini, NVIDIA ise SM başına dört adet bulunan büyük tensör/matris birimini kullanıyor. Intel, yaklaşımında hesaplama uygulamaları açısından biraz aşırıya kaçmış görünüyor.
Bir başka farklı tasarım da işlem bloğundaki yükleme/depolama (LD/ST) birimleri. Yukarıdaki basit diyagramda gösterilmeyen bu birimler, iş parçacıklarından gelen bellek talimatlarını yöneterek verileri kayıt dosyası ile L1 önbelleği arasında taşıyor. Ada Lovelace, SM bölümü başına dört adet olmak üzere toplamda 16 adet (Ampere ile aynı) birime sahip. RDNA 3 yine RDNA 2 ile aynı ve her CU doku ünitesinin bir parçası olarak özel LD/ST devresi barındırıyor.
Intel’in Xe-HPG sunumunda Xe-Core başına sadece bir LD/ST gösteriliyor ancak gerçekte muhtemelen içinde daha fazla ayrı birimden oluşuyor. Bununla birlikte, OneAPI için optimizasyon kılavuzunda, bir diyagram LD/ST’nin her seferinde bir kayıt dosyası üzerinden döngü yaptığını göstermekte. Eğer durum böyleyse, Alchemist her zaman maksimum önbellek bant genişliği verimliliğine ulaşmakta zorlanacak çünkü çünkü tüm dosyalar aynı anda sunulmamakta.
Alchemist Mimarisinin Ayrıntıları
Alchemist aslında 12. Nesil entegre Xe Grafikleriyle bazı ortak noktalara ve özelliklere sahip. Ancak mimariyle birlikte kullanılan yeni teknolojiler, Intel GPU’ları Arc öncesi ve Arc sonrası olarak nitelendirmemizi sağlıyor.
Xe-HPG GPU’ların ana yapı taşını Xe-Core (Xe-Çekirdeği) olarak bilinen birimler oluşturuyor. Bu isimlendirme ilk olarak Alchemist ile kullanıldı. Öte taraftan, “Xe Vector Engine (Xe Vektör Motoru-XVE)” adında vektör motorları mevcut. Bazı yerlerde bu birimlerin isminin Execution Unit (Yürütme Birimi-EU) olarak anıldığını da görebilirsiniz.

Intel, 16 adet XVE’yi, Matrix Engines (XMX) bloklarını, Load/Store birimini ve L1 önbelleği Xe-Core ismini verdiğimiz bir ünitede gruplandırıyor. Ayrıca her Xe-Core’a bağlı Thread Sorting Unit (İş Parçacığı Sıralama Birimi-TSU), BVH Cache (ışın izleme için) ve diğer ışın izleme birimleri (BVH ışın/kutu kesişimi ve ışın/üçgen kesişimi için) var.
Her bir XVE döngü başına sekiz FP32 işlemi gerçekleştirebiliyor. İsimlendirmeler farklı olabilir, ancak bunlar AMD ve NVIDIA gölgelendiricileriyle eşdeğer. Bu arada her Xe-Core’un 128 gölgelendirici çekirdeğe sahip olduğunu ekleyelim.
Xe-Core’ların hepsi SIMD (tek komut çoklu veri) tasarımına dayanıyor. Intel, Arc Alchemist ile DirectX 12 Ultimate özellik setinin tamamını karşılamak için gölgelendiricileri geliştirdiğini belirtiyor.

XVE’ler ayrıca INT ve EM desteği gibi ek işlevlere de sahip. Grafik iş yüklerinde çok sayıda bellek adresi hesaplaması vardır, bu da INT işlevselliğinin genellikle yardımcı olduğu yerdir. Bu tür işlevler kriptografik karma için de kullanılabilir. EM, “Genişletilmiş Matematik” anlamına gelirken karmaşık işlemlerin yapılmasında rol oynuyor. INT yürütme portu, INT ve FP hesaplamalarına göre daha az kullanılan EM işlevselliği ile paylaşılıyor.
Bu arada, XMX bloklarını NVIDIA’nın Tensor çekirdekleriyle karşılaştırabiliriz. Her XMX birimi FP16/BF16 (16 bit kayan nokta/beyin kayan nokta), INT8 (8 bit tamsayı) ya da INT4/INT2 (4 bit/2 bit tamsayı) verilerini işleyebiliyor. Bu bloklar, Intel’in XeSS yükseltme algoritması da dahil olmak üzere derin öğrenme iş yüklerinde görev yapıyor. Ayrıca çok sayıda düşük hassasiyetli sayı işlemine ihtiyaç duyan herhangi bir iş yükünde faydalı olabiliyor, her XMX bloğu saat başına 128 FP16, 256 INT8 veya 512 INT4/INT2 işlemi yapabiliyor.
İşlemci üç yürütme portuna (FP, INT/EM ve XMX) aynı anda talimat gönderebilirken, üç yürütme bloğu da aynı anda aktif olabiliyor. Özetle, tam olarak aynı olmasa da NVIDIA’nın mimarileriyle benzerlik var.
Bir adım yukarı çıkarsak Intel, NVIDIA’nın Grafik İşleme Kümesi’ne (Graphics Processing Cluster-GPC) benzeyen Render-İşleme Dilimi (Render Slice) adını verdiği bir yapılandırma kullanmış. Bu bölümler dört Xe-Core’dan oluşuyor ve daha sonra doku birimleri (slaytlarda Sampler, yani örnekleyici) ve Render Outputs (ROP’lar, görsellerde “Pixel Backend”) ile diğer bazı donanımları bir araya getiriyor.
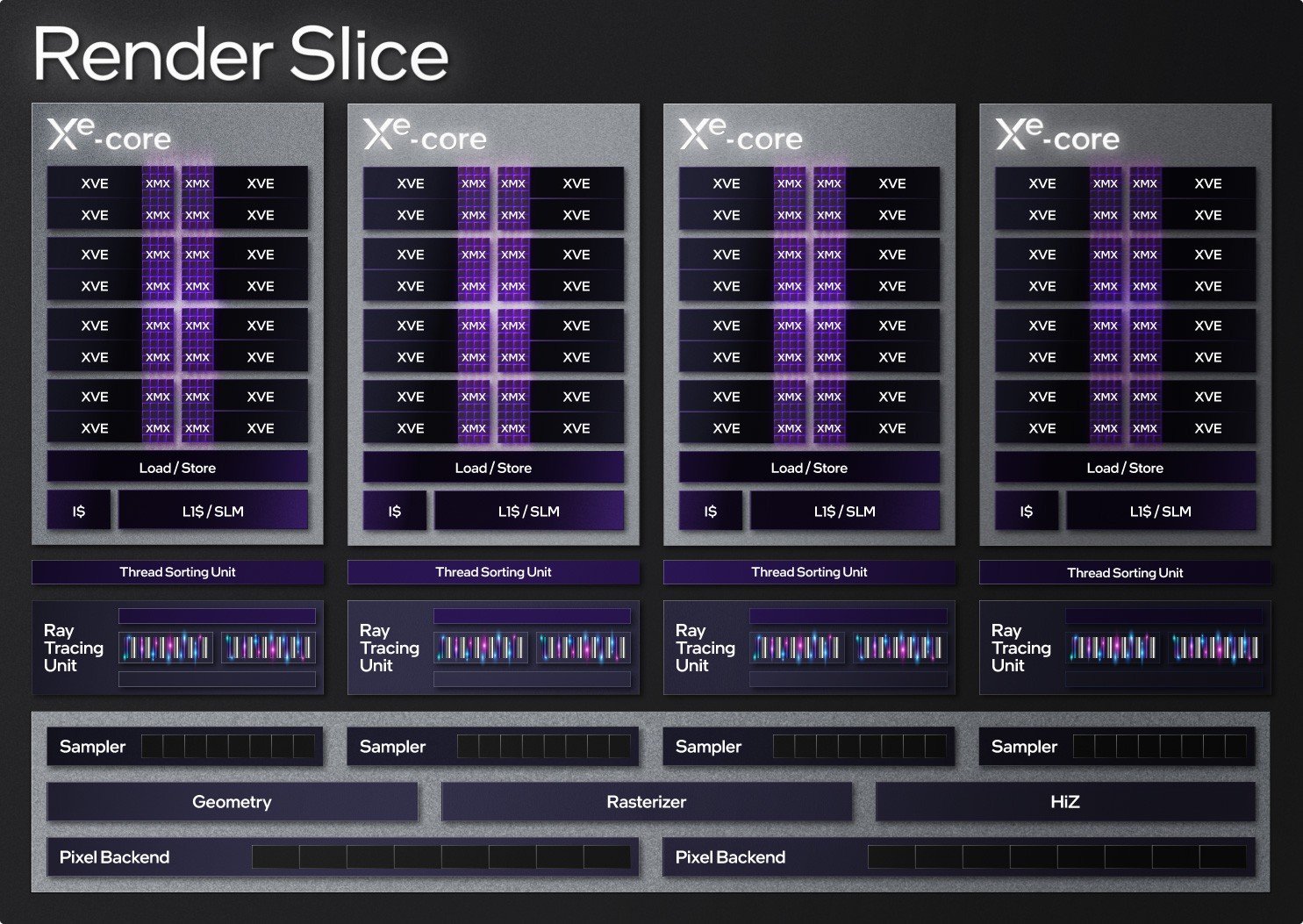
Arc Alchemist’in temelinde iki ana tasarım var; biri iki render dilimi ve sekiz adede kadar Xe-Core, diğeri ise sekiz adede kadar render dilimi olan daha büyük bir tasarım. Arc A770 ekran kartında yer alan ACM-G10 isimli GPU, tüm birimleri etkinleştirilmiş büyük tasarımı kullanıyor. Yani 32 Xe-Core içeren bir yapılandırma. Daha zayıf bir ekran kartı olan Arc A380 ise tam olarak etkinleştirilmiş daha küçük yapılandırmayı kullanmakta.
Arc A770’de 16 MB’a kadar büyük bir L2 önbellek ve tüm dilimleri birbirine bağlayan bellek yapısı mevcut. NVIDIA’nın Ada Lovelace ve yeni AD102 GPU’su 96 MB’a varan L2 önbelleğe sahip. Böyle baktığımızda A770’in sahip olduğu bellek küçük görünebilir. Ancak AD102’nin farklı segmentlerde sunulan RTX 4090 ekran kartında kullanıldığını belirtelim. GA102 GPU ile gelen RTX 3090 serisi ise yalnızca 6 MB L2 önbelleğe sahipti.

Blok şeması ayrıca AV1, VP9, HEVC ve H.264 dahil olmak üzere çeşitli video/görüntü kodeklerini işleyen Xe Medya Motorunu da gösteriyor. Hem büyük hem de küçük Arc GPU’larda iki adet tam medya motoru (MFX) bulunmakta. Bunlar ayrı akışlar üzerinde çalışabiliyor veya kodlama verimini iki katına çıkarmak için hesaplama güçlerini birleştirebiliyor.

Görselin sol kısımda dörtlü Display Engine (Ekran-Görüntü Motoru), PCI Express bağlantı birimi, Copy Engine (Kopyalama Motoru) ve Memory Controller’ı (Bellek Kontrolcüsü) görüyoruz. GDDR6 kontrolcüleri aslında GPU’nun dışına yerleştirilmiş ve harici belleğe bağlanıyor. ACM-G10, sekiz adede kadar 32 bit bellek kontrolcüsü taşıyor. Bu arada, blok diyagramın gerçek çip düzenini tam olarak yansıtmadığını belirtelim.
DirectX 12 Ultimate ve Ray Tracing
Arc Alchemist, DirectX 12 Ultimate özellik setinin tamamını destekliyor. Bu birkaç anahtar teknolojinin kullanılacağını gösteriyor. En önemlisi ışın izleme desteği. Diğer taraftan DX 12 Ultimate ile Variable Rate Shading (Değişken Oranlı Gölgelendirme), Sampler Feedback (Örnekleyici Geri Bildirimi) ve Mesh Shading gibi önemli özellikleri de hatırlatalım.
NVIDIA’nın Son Mimarisi: Ada Lovelace
Son olarak AMD’nin DCU ve Intel’in Xe-Core’u ile eşdeğer Çoklu Akış İşlemcilerine (Streaming Multiprocessor-SM) gelelim. Yeşil ekibin mühendisleri 2018 yılında sunulan Turing mimarisinden beri bu birimlerin üzerinde büyük oynamalar yapmadı. Hatta Ada Lovelace ve Ampere bu konuda neredeyse aynı.
Bazı birimler performansın veya özellik setlerinin geliştirilmesi için değişti, ancak geri kalan şeyler eskisi ile benzer. NVIDIA, tasarladığı çiplerin ince detaylarını ve özellikleri hakkında çok fazla bilgi veren bir şirket değil. Intel daha fazla ayrıntı veriyor fakat bu bilgiler genellikle göz önünde olmayan belgelerin içine yerleştiriliyor.
Özetleyecek olursak, SM dediğimiz birimler dört bölüme ayrılmakta. Her bölümün kendi L0 komut önbelleği, iş parçacığı zamanlayıcısı/gönderme birimi ve SIMD32 işlemciyle eşleştirilmiş kayıt dosyasının 64 kB’lık bir bölümü var.
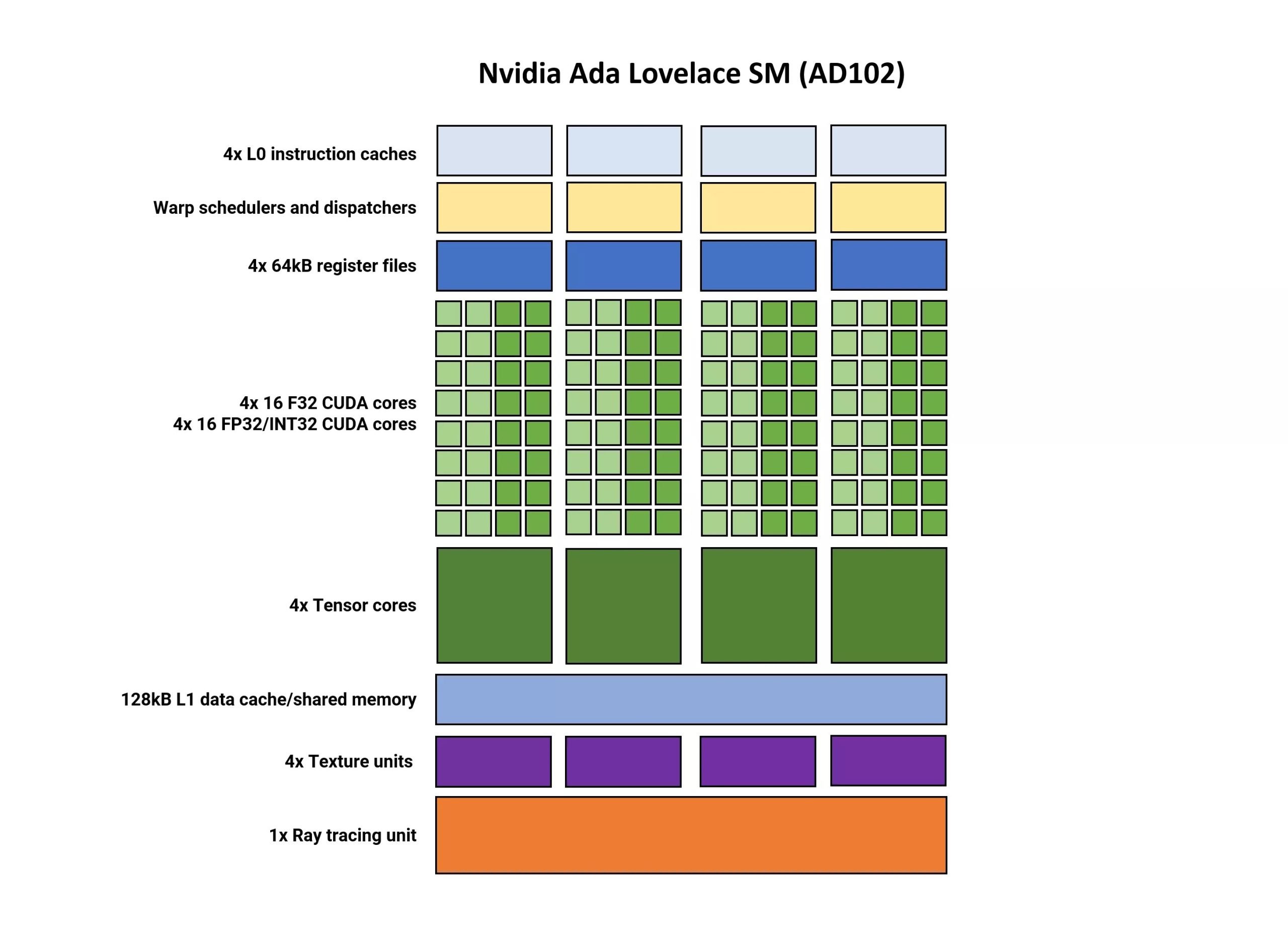
Tıpkı AMD RDNA 3 mimarisinde olduğu gibi, her bölümün biri FP32 talimatlarıyla diğeri FP32 veya INT32 talimatlarıyla olmak üzere iki iş parçacığını eşzamanlı olarak işleyebildiği ikili komutları desteklemekte.
Tensor Çekirdekleri son mimariyle birlikte dördüncü sürüme yükseldi, ancak kayda değer tek değişiklik FP8 Transformer Engine’in (Hopper çiplerde bulunan) dahil edilmesi. Ham verimlilik rakamları ise değişmedi.
Düşük hassasiyetli float formatının eklenmesiyle birlikte GPU’lar yapay zeka eğitim modelleri için daha uygun hale geldi. Tensor çekirdekleri aynı zamanda Ampere’nin verimin iki katına kadar çıkabilen seyreklik özelliğini de sunuyor.
Bir diğer önemli değişim de Optik Akış Hızlandırıcı (Optical Flow Accelerator-OFA) motoruyla ilgili. Bu devre, DLSS algoritmasının bir parçası olarak kullanılan optik akış alanı üretiyor. Ampere’deki OFA’nın performansının iki katına çıkmasıyla elde edilen ekstra verimlilik, DLSS 3 ile birlikte kullanılıyor.
Ada mimarisinin SM birimleri Ampere ile çok benzer olsa da, RT Çekirdeklerinde önemli değişiklikler var. Şimdi kısaca bir özet geçelim.
3. Nesil Ray Tracing Çekirdekleri
Işın izleme bir kez daha büyük önem kazanıyor ve üç yeni teknoloji hayatımıza giriyor: Shader Execution Reordering (SER), Opacity Micro-Maps (OMM) ve Displaced Micro-Meshes (DMM). Bu yeniliklerin tümüyle birlikte çeşitli iyileştirmeler sunuluyor, ancak geliştiricilerin yeni teknolojileri oyunlarına uygulaması gerekecek.

OMM Motoru, yapraklar, parçacıklar ve çitler için sıklıkla kullanılan dokuların çok daha iyi işlenmesini sağlıyor. DMM Motoru ise 20 kata kadar daha az BVH depolama alanı ile 10 kata kadar daha hızlı Bounding Volume Hierarchy (BVH) oluşturma süresi sunarak geometrik olarak karmaşık sahnelerin gerçek zamanlı ışın takibini mümkün hale getiriyor.
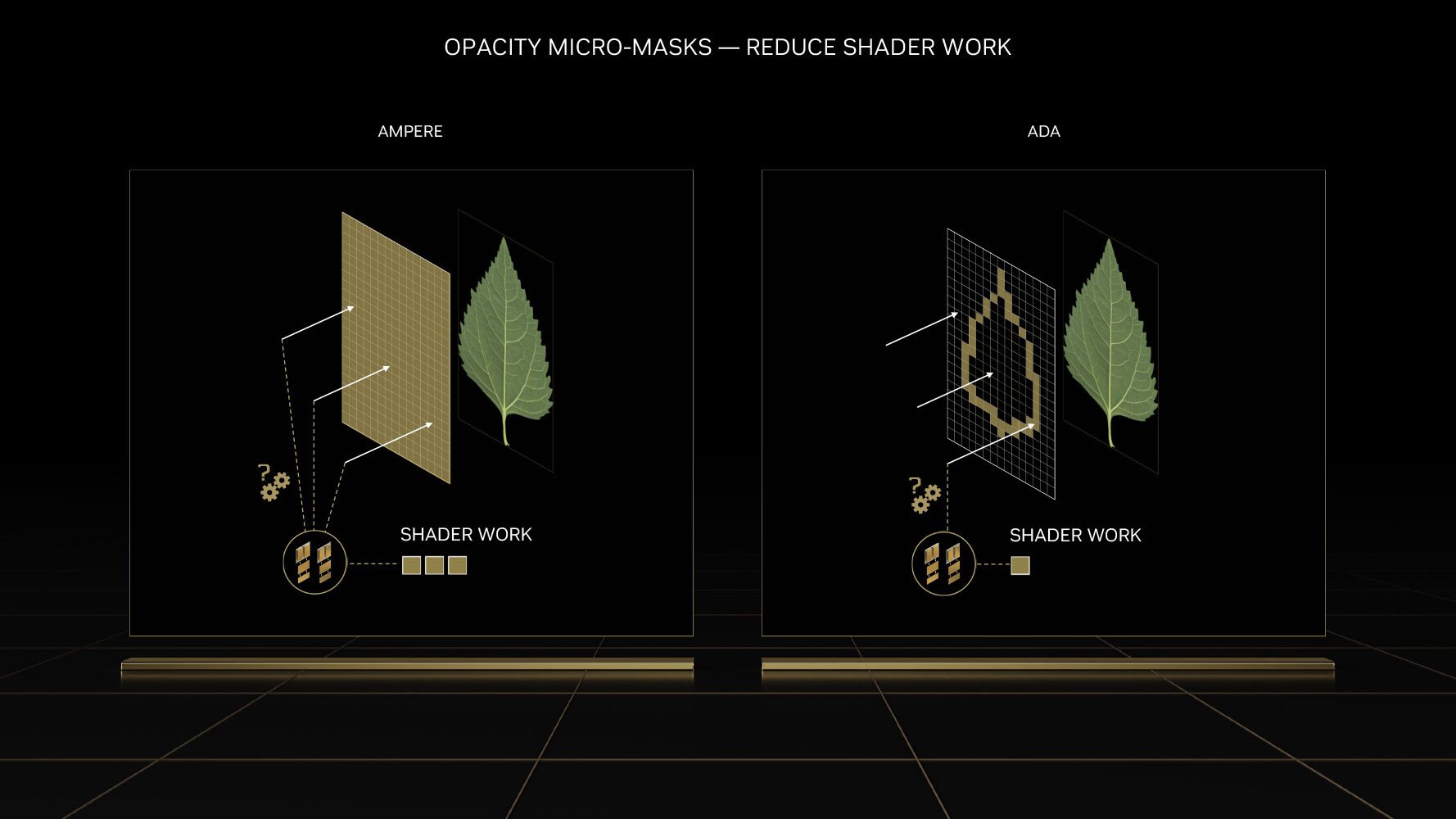
Ada GPU içinde yer alan ışın izleme birimleri, Faster Ray-Triangle Intersection Throughput (Işın-Üçgen Kesişme Verimi) açısından iki kat daha gelişmiş ve bu da geliştiricilerin sanal dünyalarına daha fazla ayrıntı eklemelerini sağlıyor.
Shader Execution Reordering
Gelişmiş ışın izleme, bir sahne boyunca çok sayıda farklı nesneye çarpan, çok sayıda ışının hesaplamasını gerektiriyor. Böylelikle çekirdekler için farklı iş yükleri doğmuş oluyor. Shader Execution Reordering (SER) teknolojisi, önceden verimsiz olan bu iş yüklerini dinamik olarak yeniden düzenleyerek çok daha verimli hale getiriyor. SER, ışın izleme işlemleri için gölgelendirici performansını 3 kata kadar ve oyun içi kare hızlarını %25’e kadar artırabiliyor.
4. Nesil Tensor Çekirdekleri
Derin öğrenme ve yapay zeka iş yüklerine gelince, yine bu alanda büyük gelişmeler kaydedildiğini görüyoruz. Ada’nın dördüncü nesil Tensor çekirdekleri, ilk olarak Hopper H100 veri merkezi GPU’su ile tanıtılan FP8 Transformer Engine’i kullanarak verimi 5 kata kadar artırıyor ve 1.4 Tensor-petaFLOPS’luk güç ortaya çıkıyor.
Transformer Engine sayesinde FP16 yerine FP8 kullanabilen algoritmalar için Tensor çekirdeği başına hesaplama becerisi iki katına çıkıyor.
AV1 Kodek Desteği
Önceki nesil Ampere ekran kartlarında AV1 kod çözme desteği sunulsa da AV1 kodlama desteği sunulmuyordu. Ada mimarisi üzerine inşa edilen ekran kartları, AV1 kodlama desteği sunan sekizinci nesil NVIDIA Encoder’a (NVENC) sahip olacak. Böylelikle yayıncılar ve video işiyle uğraşanlar için yeni olanaklar sağlanacak. AV1 kodek, H.264’ten %40 daha verimli. Ayrıca 1080p’de yayın yapan kullanıcıların aynı bit hızı ve kalitede çalışırken yayın çözünürlüklerini 1440p’ye yükseltmelerine imkan verecek.
Ada GPU’lar ayrıca çift NVENC kodlayıcı ile destekleniyor. Bu gelişim ise profesyonel video düzenleme için 8K/60 veya dört adet 4K/60 video kodlamasına olanak sağlıyor. DaVinci Resolve, Adobe Premiere Pro için popüler Voukoder eklentisi ve Çin’in en iyi video düzenleme uygulaması olan Jianying, AV1 desteğinin yanı sıra çift kodlama desteğiyle kullanıma sunuldu.
NVIDIA, AMD ve Intel
SM, Xe-Core ve DCU yeteneklerini standart veri formatları için saat döngüsü başına işlem sayısına bakarak karşılaştırabiliriz. Ek olarak, bunların en yüksek rakamlar olduğunu ve gerçekte ulaşılabilecek rakamlar olmadığını hatırlatalım.
| Saat Başına İşlem | Ada Lovelace | Alchemist | RDNA 3 |
| FP32 | 128 | 128 | 256 |
| FP16 | 128 | 256 | 512 |
| FP64 | 2 | – | 16 |
| INT32 | 64 | 128 | 128 |
| FP16 matrix | 512 | 2048 | 256 |
| INT8 matrix | 1024 | 4096 | 256 |
| INT4 matrix | 2048 | 8192 | 1024 |
NVIDIA’nın rakamları Ampere’den bu yana değişmezken, RDNA 3’ün rakamları bazı alanlarda iki katına çıktı. Alchemist ise matris işlemleri söz konusu olduğunda başka bir seviyede, ancak bunların en yüksek teorik değerler olduğunu tekrar belirtelim.
Intel’in tıpkı NVIDIA gibi veri merkezi ve bilgi işleme ağırlık verdiği düşünüldüğünde, mimarinin matris işlemlerine bu kadar fazla kalıp alanı ayırdığını görmek şaşırtıcı değil. FP64 özelliğinin olmaması bir sorun değil çünkü bu veri formatı oyunlarda pek kullanılmıyor ve bu işlevsellik Xe-HP mimarisinde mevcut.

Ada Lovelace ve Alchemist, matris/tensör işlemleri söz konusu olduğunda teorik olarak RDNA 3’ten daha güçlü. Bahsettiğimiz tüm mimariler öncelikle oyun iş yükleri için kullanılıyor ve özel birimler çoğunlukla sadece DLSS ve XeSS’de yer alan algoritmalar için hızlandırma sağlıyor. Özel birimler, bir görüntüyü yapaylıklara karşı tarayan ve düzelten bir evrişimli otomatik kodlayıcı sinir ağı (convolutional auto-encoder neural network-CAENN) kullanmakta.
AMD’nin zamansal yükselticisi (FidelityFX Super Resolution-FSR), öncelikle Lanczos yeniden örnekleme yöntemine ve ardından DCU’lar aracılığıyla işlenen bir dizi görüntü düzeltme rutinine dayandığından CAENN kullanmıyor. FSR’nin bir sonraki FSR 3 sürümü ise biraz daha farklı. Şirket, Fluid Motion Frames (Akışkan Hareket Çerçeveleri) adı verilen yeni bir özellik kullanmaya başladı. FSR’ın sunduğu FPS değerlerini iki katlayacağı iddia edilen teknoloji, DLSS 3’te olduğu gibi kare oluşturma teknolojisi içerecek. Ancak teknolojinin herhangi bir matris işlemi içerip içermediği henüz net değil.
Artık Daha Önemli: Ray Tracing (Işın İzleme)
Intel, Alchemist mimarisini kullanan Arc ekran kartlarıyla birlikte ışın izleme teknolojileri sunarak AMD ve NVIDIA’ya rakip oldu. Mavi ekip de rakipleri gibi ışın izleme kullanımıyla ilgili çeşitli algoritmalar için özel hızlandırıcılar kullanıyor.
AMD
AMD’nin grafik yongalarında Işın Hızlandırıcı (Ray Accelerator-RA) denilen birimler yer almakta. Her CU’da bir adet RA bulunuyor. Işın Hızlandırıcılarındaki en büyük değişikliğe gelince, sınırlayıcı hacim hiyerarşilerinin (bounding volume hierarchies-BVH) geçişini iyileştirmek için donanım eklendi. Bunlar, 3D dünyada bir ışınının hangi yüzeye çarptığını belirlemeyi hızlandırmak için kullanılan veri yapılarıdır.
RDNA 2’de tüm bu işler Hesaplama Birimleri aracılığıyla işleniyordu ve bir dereceye kadar hala da öyle. Bunun yanında, Microsoft’un ışın izleme API’si olan DXR ile bağlantılı olarak ışın işaretlerinin yönetimi için donanım desteği sunuldu.
Özünde AMD, önceki mimaride sunduğu sistemin genel verimliliğini artırmaya odaklandı. Ayrıca donanım, box sorting (geçişi daha hızlı hale getiren) ve ayıklama algoritmalarını (boş kutuları test etmeyi atlamak için) iyileştirmek için güncellendi. Önbellek sistemindeki iyileştirmelerle birlikte AMD, RDNA 2’ye kıyasla aynı saat hızında %80’e kadar daha fazla ışın izleme performansı sağlandığını belirtiyor. Bu tür iyileştirmeler ışın izleme kullanan oyunlarda saniyede %80 daha fazla kare anlamına gelmiyor.
Intel
Intel ışın izleme konusunda yeni olduğu için böyle bir iyileştirme söz konusu değil. Bunun yerine, RT birimlerinin ışınlar ve üçgenler arasında BVH geçişini ve kesişme hesaplamalarını gerçekleştirdiği söyleniyor. Bu da demek oluyor ki Intel’in sistemi de AMD ve NVIDIA ile benzer.
Intel tarafında detaylar daha kısıtlı. Ancak her RT biriminin BVH verilerini depolamak için belirtilmemiş büyüklükte bir önbelleğe ve SIMD kullanımını iyileştirmek için ışın gölgelendirici iş parçacıklarını analiz etmek ve sıralamak için ayrı bir birime sahip olduğunu biliyoruz.
Her Xe-Core bir RT ünitesiyle eşleştirilerek Render Slice başına toplam dört ünite elde ediliyor. A770’in oyunlarda ışın izleme etkinleştirilerek yapılan bazı testleri, Intel’in uyguladığı yapılar ne olursa olsun, Alchemist’in ışın izlemedeki genel kapasitesinin en az Ampere yongalarında bulunan kadar iyi olduğunu ve RDNA 2 modellerinden biraz daha iyi olduğunu gösteriyor. Özetle mavi ekibin yeni bir oyuncu olmasına rağmen ışın izleme konusunda başarılı olduğunu söylemek mümkün.
NVIDIA
NVIDIA, Ada Lovelace mimarisiyle birlikte performans artışı için önemli değişiklikler yaptı. Işın-üçgen kesişimi hesaplamaları için hızlandırıcıların iki kat daha fazla verim sağladığı ve opak olmayan yüzeyler için BVH geçişinin artık iki kat daha hızlı olduğu söyleniyor. İkinci gelişim, bir ağaçtaki yapraklar gibi alfa kanallı (şeffaf) dokular kullanan nesneler için önem taşımakta.
Yeşilliler herkesin bildiği gibi ışın izleme konusunun öncüsü ve bu işte lider konumda. Biraz önce değindiğimiz üzere, son Ada Lovelace mimarisiyle de hem Tensor hem Ray Tracing bazlı değişiklikler yapıldı. Şirket böylelikle liderliğini perçinlemiş oldu.
RT çekirdekleri CUDA gibi çok yönlü değildir. Daha fazla verim elde etmek amacıyla özel hesaplamalar veya algoritmalar için özel bir mimariyle desteklenmekte. Bu mimari, oyunlarda ışın izleme komutlarını tanımlamak ve hızlandırmak üzere geliştirildi. Her nesilde de iyileşmeye devam ediyor.
NVIDIA, AMD’ye benzer şekilde her bir SM biriminin içine bir adet RT çekirdeği dahil ediyor. RTX 4090 üzerinden gidecek olursak, 128 SM’nin yer aldığı AD102 GPU’da 128 adet RT çekirdeği görev yapıyor.


