

Uzun zamandır bilgisayar kullanıyor olsanız bile “Tensor Çekirdeği” terimini özellikle son birkaç yılda sık sık duymuş olmalısınız. NVIDIA tarafından geliştirilen ve Tensor Core olarak bilinen bu çekirdekler GPU içerisinde özel bir birim olarak yer alıyor.

NVIDIA, “RTX” adını taşıyan modellerle birlikte ekran kartlarında Tensor çekirdeklerine yer vermeye başladı. Tensor çekirdeklerinin yanı sıra, RT (Ray Tracing) çekirdekleri de artık önemli bir rol oynuyor. Bu çekirdekler gölgelendiriciler için kullanılan normal çekirdeklerden ayrı olarak konumlanıyor. Peki yeşil takımın GPU’larına güç veren bu birimler tam olarak nedir ve ne için kullanılıyor?
Tensor Mantığı
Tensör çekirdeklerinin tam olarak ne yaptığını ve ne amaçla kullanılabileceğini öğrenmek için işin detayına insek iyi olur. Mikroişlemciler, hangi formda olurlarsa olsunlar sayılar üzerinde matematik işlemleri (toplama, çarpma, vb.) gerçekleştirirler.
Bazen bu sayıların bir arada gruplanması gerekir çünkü birbirleriyle bağlantılılar. Örneğin bir çip grafik oluşturmak için veri işlerken, aynı zamanda bir ölçeklendirme faktörü için tek bir tam sayı değeriyle (+2 veya +115 gibi) veya bir noktanın koordinasyonları için bir grup kayan noktayla (+0,1, -0,5, +0,6) ilgileniyor olabilir.
Tensör, hepsi birbirine bağlı olan diğer matematiksel nesneler arasındaki ilişkiyi tanımlayan matematiksel bir nesnedir. Genellikle, dizi boyutunun aşağıda gösterildiği gibi görüntülenebileceği bir sayı dizisi olarak tanımlanırlar.
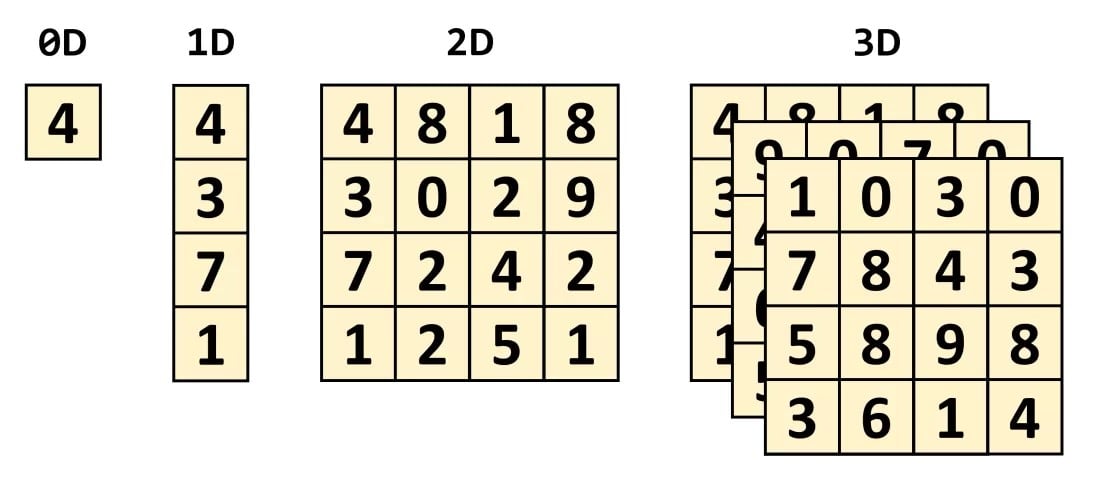
Elde edebileceğiniz en basit tensör türü sıfır boyuta sahip olur ve tek bir değerden oluşur (skaler nicelik). Boyut sayısını artırmaya başladığımızda diğer yaygın matematik yapılarıyla karşılaşabiliriz:
- 1 boyut = vektör
- 2 boyut = matris gibi.
Bir skaler 0 x 0 tensördür, bir vektör 1 x 0 ve bir matris 1 x 1’dir. Ancak işleri basitleştirmek ve grafik işlemcilerindeki tensör çekirdeklerine odaklanmak için tensörleri sadece matris şeklinde ele alacağız.
Matrislerle yapılan en önemli matematik işlemlerinden biri çarpma işlemidir. Şimdi her ikisi de 4 satır ve sütun değerine sahip iki matrisin nasıl çarpıldığına bir göz atalım:
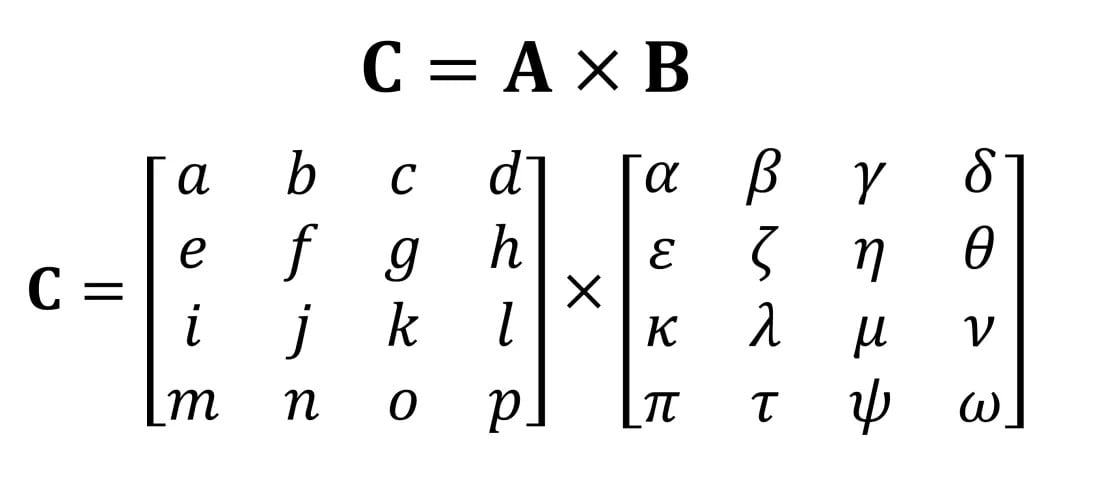
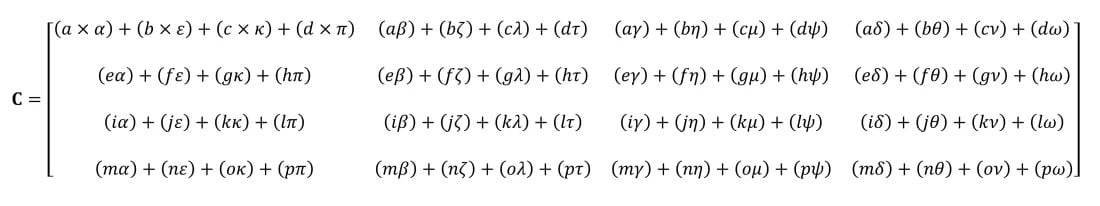
Gördüğünüz üzere, basit bir matris çarpımı hesaplaması için bir ton işlem gerekiyor. Bugün piyasadaki her CPU bu işlemleri yapabiliyor. Bu da herhangi bir masaüstü, dizüstü bilgisayar veya tabletin temel tensörleri işleyebileceği anlamına geliyor.
Yukarıdaki örnek 64 çarpma ve 48 toplama içeriyor; her küçük çarpım, tensör için nihai değerin bir yerde saklanabilmesi için diğer 3 küçük çarpımla toplanmadan önce bir yerde saklanması gereken bir değerle sonuçlanıyor. Dolayısıyla, matris çarpımları matematiksel olarak basit olsa da hesaplama açısından çok yoğundur. Özetle, çok sayıda kayıt kullanılması, önbelleğin çok sayıda okuma ve yazma işlemiyle başa çıkması gerekir.
CPU ve GPU
AMD ve Intel’in işlemcileri yıllar boyunca çeşitli komut setleri (MMX, SSE ve AVX gibi) sundu. Dahil edilen komut işleme yetenekleri, işlemcinin aynı anda çok sayıda kayan nokta sayısını işlemesine olanak tanıyor; yani tam olarak matris çarpımlarının ihtiyacı olan şey.
Ancak SIMD (tek komut çoklu veri-single instruction multiple data) işlemlerini gerçekleştirmek için özel olarak tasarlanmış belirli bir işlemci türü vardır: grafik işleme birimleri (GPU’lar).
Farklı Kullanım Alanları
Tensör matematiği fizik ve mühendislikte son derece kullanışlıdır. Akışkanlar mekaniği, elektromanyetizma ve astrofizikteki her türlü karmaşık problemi çözmek için kullanılır, ancak bu sayıları kırmak için kullanılan bilgisayarlar matris işlemlerini büyük CPU kümeleri üzerinde yapma eğilimindedir.
Tensör kullanmayı seven bir başka alan da makine öğrenimi, özellikle de derin öğrenme alt kümesidir. Bu noktada, sinir ağı adı verilen muazzam dizilerdeki devasa veri koleksiyonları işlenir.
Bu nedenle tüm büyük derin öğrenme süper bilgisayarları GPU’larla, çoğunlukla NVIDIA imzalı GPU’larla destekleniyor. Ancak bazı şirketler kendi tensör çekirdekli işlemcilerini üretmeyi istedi. Örneğin Google, 2016 yılında ilk TPU’sunu (tensör işleme birimi) duyurdu ancak bu çipler o kadar özelleştirilmiştir ki matris işlemlerinden başka bir şey yapamıyorlar.
GPU ile Hesaplama
Grafik dünyasında büyük miktarda verinin aynı anda vektörler şeklinde hareket ettirilmesi ve işlenmesi gerekir. GPU’ların paralel işleme kabiliyeti onları tensörlerin işlenmesi için ideal hale getirmekte ve günümüzde hepsi GEMM (General Matrix Multiplication-Genel Matris Çarpımı) adı verilen bir işlemi desteklemekte.
Bu, iki matrisin birlikte çarpıldığı ve cevabın daha sonra başka bir matrisle toplandığı bir ‘birleştirilmiş’ işlemdir. Matrislerin hangi formatta olması gerektiği konusunda bazı önemli kısıtlamalar da vardır, bunlar her matrisin sahip olduğu satır ve sütun sayısı etrafında döner.

Matris işlemleri, yalnızca bu işlemlere adanmış donanımlarda işlendiklerinde daha iyi çalışırlar. Aralık 2017’de NVIDIA, Volta mimarisine sahip GPU ile birlikte yeni bir ekran kartı piyasaya sürdü. Kartlar profesyonel pazarlara yönelikti, bu nedenle hiçbir GeForce modeli bu çipi kullanmadı. Günümüzdeki GeForce ekran kartlarının tümünde Tensor Çekirdekleri yer alıyor. Ancak o yıllarda Volta, sadece tensör hesaplamaları için çekirdeklere sahip olduğundan dolayı özel bir yere sahipti.
NVIDIA’nın bu özel çekirdekleri, FP16 değerleri (16 bit boyutunda kayan nokta sayıları) veya FP32 toplama ile FP16 çarpımı içeren 4 x 4 matrisler üzerinde saat döngüsü başına 64 GEMM taşıyacak şekilde tasarlandı. Böyle tensörlerin boyutu çok küçüktür, bu nedenle gerçek veri kümelerini işlerken, çekirdekler daha büyük matrislerin küçük bloklarını kırarak nihai sonucu oluşturur.
GPU devi, bir yıldan kısa bir süre sonra Turing mimarisini piyasaya sürdü. Bu kez tüketici sınıfı GeForce modelleri de tensör çekirdekleri barındırıyordu. Sistem INT8 (8-bit tamsayı değerleri) gibi diğer veri formatlarını destekleyecek şekilde güncellenmişti, ancak bunun dışında Volta’da olduğu gibi çalışmaya devam ediyorlardı.
Sonrasında Ampere mimarisiyle birlikte Tensor çekirdeklerinin performansı (64’ten döngü başına 256 GEMM) artırıldı. Ayrıca şirket daha fazla veri formatı ekledi ve seyrek tensörleri (içinde çok sayıda sıfır olan matrisler) çok hızlı bir şekilde işleme yeteneği sağladı.

Şirket her geçen nesilde Tensor çekirdeklerini geliştiriyor. Ada Lovelace mimarisi ve RTX 40 serisi ekran kartlarıyla birlikte 4. Nesil Tensor çekirdekleri kullanılmaya başladı. NVIDIA, derin öğrenme ve yapay zeka iş yükleri konusunda büyük gelişmeler kaydetti. Ada’nın dördüncü nesil Tensor çekirdekleri, ilk olarak Hopper H100 veri merkezi GPU’su ile tanıtılan FP8 Transformer Engine’i kullanarak verimi 5 kata kadar artırıyor ve 1.4 Tensor-petaFLOPS’luk güç ortaya çıkıyor. Bunun yanında, Transformer Engine sayesinde FP16 yerine FP8 kullanabilen algoritmalar için Tensor çekirdeği başına hesaplama becerisi iki katına çıkıyor.
Programcılar için Volta, Turing, Ampere ve Ada Lovelace çiplerinden herhangi birindeki tensör çekirdeklerine erişmek kolay: kodun API ve sürücülere tensör çekirdeklerini kullanmak istediğinizi belirtmek için bir ‘flag’ kullanması, veri türünün çekirdekler tarafından desteklenen bir tür olması ve matrislerin boyutlarının 8’in katı olması gerekir. Bundan sonra donanım diğer her şeyi otomatik olarak halleder.
GeForce RTX: Tüketici Sınıfı Ekran Kartlarında Tensor Çekirdekleri
Tensor çekirdekleri iş hayatını kolaylaştırma konusunda çok başarılı. Ancak GeForce RTX serisi bir kart kullanıyorsanız ve karmaşık şeylerle uğraşmıyorsanız bu özel birimler ne işinize yarayacak?
Tensor, normal işleme, video kodlama veya kod çözme için kullanılmaz. Ancak NVIDIA, 2018’de tüketici ürünlerine (Turing GeForce RTX) tensör çekirdeklerini dahil ederken bir başka teknoloji daha tanıttı: DLSS – Deep Learning Super Sampling.
Bu kadar karışık hesaplama muhabbetinden sonra şimdi her şey biraz daha yerine oturmuş olmalı. DLSS teknolojisi bildiğiniz gibi artık vazgeçilmez hale geldi ve yeni oyunların çoğuna entegre ediliyor.
DLSS, bir kareyi düşük çözünürlükte işledikten sonra monitörün doğal ekran boyutlarıyla eşleşecek şekilde sonucun çözünürlüğünü artırabilen kritik bir yükseltme teknolojisi. Örneğin 1080p’de işleyip, ardından 1400p’ye yeniden boyutlandırmak gibi. DLSS’yi bu amaçla kullandığımızda performanstan fazla ödün vermeden, daha az piksel işleyerek ekranda güzel görünen görüntüler elde edebiliyor.
NVIDIA bu teknolojiyi ilk kez kullandığı dönemde, seçilen oyunlar düşük çözünürlüklerde, yüksek çözünürlüklerde, kenar yumuşatma ile ve kenar yumuşatma olmadan çalıştırılarak analiz edildi. NVIDIA, süper bilgisayarlarında 1080p bir görüntüyü daha yüksek çözünürlüklü mükemmel bir görüntüye dönüştürmek üzere özel bir sinir ağı kullanıyor.
DLSS 1.0 sürümü harika değildi. Bazı yerlerde ayrıntılar kayboluyordu ve garip parıltılar gözlemlenebiliyor. Ayrıca bu sürüm ekran kartındaki tensör çekirdeklerini de kullanmıyordu (bu işlem NVIDIA’nın ağında yapılıyordu).
2.0 sürümü 2020’nin başlarında çıktığında bazı büyük iyileştirmeler yapıldı. Bunlardan en dikkat çekeni, NVIDIA süper bilgisayarlarının yalnızca genel bir yükseltme algoritması oluşturmak için kullanılmasıydı. DLSS’nin yeni sürümünde, işlenen kareden gelen veriler nöral modeli kullanarak pikselleri (GPU’nuzun tensör çekirdekleri aracılığıyla) işlemek için kullanılmaya başladı. Sonuç olarak Tensor Çekirdekleri çok daha önemli olmaya başladı, DLSS harika işler çıkardı.
DLSS’nin görsel çıktısı her zaman mükemmel olmayabilir. Ancak geliştiriciler, daha fazla görsel efekt ekleme veya aynı grafikleri daha geniş bir platform yelpazesinde sunma imkanına sahipler.
Örnek vermek gerekirse, DLSS genellikle “RTX özellikli” oyunlarda ışın izleme ile birlikte tanıtılıyor. GeForce RTX GPU’larda RT (Ray Tracing) çekirdekleri adı verilen ek işlem birimleri de mevcut. RT çekirdekleri, ışın-üçgen kesişimi ve BVH (bounding volume hierarchy) çaprazlama hesaplamalarını hızlandırmak için tasarlanan özel mantıksal çekirdeklerdir. Bu iki işlem, ışığın bir sahnedeki diğer nesnelerle nerede etkileşime girdiğini bulmak için kullanılır.
Özetle ışın izleme çok yoğun bir işlem. Bu nedenle oyun geliştiricileri oynanabilir performans sunmak için bir sahnede gerçekleştirilen ışın ve sekme sayısını sınırlamalı. Bu süreç taneli (pütürlü) görüntülere de neden olabilir ve işlem karmaşıklığını artıran bir denoising algoritması uygulanmalı.
DLSS 3
NVIDIA, Ada Lovelace (RTX 40) mimarisiyle birlikte yeni nesil Tensor ve RT çekirdeklerini tanıtmakla kalmadı, aynı anda DLSS’nin yeni bir sürümünü de kullanıma sundu. Kötü haber şu ki, DLSS 3 yalnızca RTX 40 serisi ekran kartlarında destekleniyor.
DLSS 3, mükemmel görüntü kalitesi ve yanıt verme özelliğini korurken performansı büyük ölçüde artıran yapay zeka destekli grafiklerde devrim niteliğinde bir atılım. DLSS Süper Çözünürlük üzerine inşa edilen DLSS 3, tamamen yeni kareler oluşturmak için Optik Çoklu Kare Üretimi ekliyor ve optimum yanıt için NVIDIA Reflex düşük gecikme teknolojisini entegre ediyor. DLSS 3, GeForce RTX 40 Serisi grafik kartlarına güç sağlayan NVIDIA Ada Lovelace mimarisinin yeni dördüncü nesil Tensör Çekirdekleri ve Optik Akış Hızlandırıcısı tarafından desteklenmekte.
DLSS Kare Üretimi evrişimli otomatik kodlayıcı 4 girdi alıyor: Mevcut ve önceki oyun kareleri, Ada’nın Optik Akış Hızlandırıcısı tarafından oluşturulan bir optik akış alanı ve hareket vektörleri ve derinlik gibi oyun motoru verileri.
RT (Ray Tracing) Çekirdeği Nedir?
RT Çekirdekleri, NVIDIA’nın oyunlarda Gerçek Zamanlı Işın İzleme (Real-Time Ray Tracing) ile ilişkili hesaplama iş yükünü sırtlamak üzere özel olarak tasarlanmış özel donanım çekirdekleridir. Tensor çekirdeklerine benzer şekilde, Ray Tracing çekirdekleri de oyunlarda temel grafik işleme için kullanılan CUDA çekirdeklerindeki üzerindeki yükü hafifletmek üzere kullanılıyor. Ancak kullanım amaçları çok farklı.
Işın İzleme (Ray Tracing) Nedir?
Gerçek hayatta gördükleriniz, gözünüzün merceği tarafından odaklanıp toplandıktan sonra gözünüzün retinasına çarpan farklı dalga boyundaki fotonların sonucudur. 3D gerçek zamanlı bilgisayar grafikleri buna benzer bir şekilde oluşturulmamıştır. Çünkü ışığın çalışma şeklini simüle etmek inanılmaz derecede yoğun hesaplama gerektirir. Işın izleme başlangıçta çevrimdışı işleme için yaygın olarak kullanılmaktaydı zira bir karenin hesaplanması saatler sürebiliyor. Hollywood’un gişe rekorları kıran animasyonlu filmlerinde görsel efektler için ışın izleme bolca kullanılıyordu.
RT çekirdekleri, bir sahne boyunca sanal ışık ışınlarını izlemek için gereken temel matematik işlemlerini hızlandırmak üzere görev yapıyor. Elbette yine her şey gerçek hayattakiyle aynı değil. Ancak simülasyonlar sayesinde ışıklandırma yapılabiliyor, her şey daha gerçekçi bir görünüm kazanıyor.
RT Çekirdeğinin Görevleri
RT çekirdekleri CUDA gibi çok yönlü değildir. Daha fazla verim elde etmek amacıyla özel hesaplamalar veya algoritmalar için özel bir mimariyle desteklenmekte. Bu mimari, oyunlarda ışın izleme komutlarını tanımlamak ve hızlandırmak üzere geliştirildi.

CUDA çekirdekleri, genel hesaplama işlerini yürütmek üzere, daha genel amaçlar için çalışır. Yeni nesil grafik işlemcilerde binlerce CUDA çekirdeği bulunur. Bunlar ekranda gördüğünüz her pikselin gölgelendirilmesinde ve modern geleneksel grafiklerde gördüğünüz diğer tüm efektleri oluşturmak üzere hesaplamalar yapar.
Kısacası, bir ışın izleme hesaplama işlemi ortaya çıktığında ekran kartının işlem hattına RT çekirdekleri de dahil olur ve bu görevi üstlenir. Yani ışın izlemeyle alakalı iş yüklerini RT çekirdekleri devralır, ardından sahneyi işlemek ve pikselleri oluşturmak için hesaplamalar yapar.







{kind=link}