

Eğer NVIDIA markalı bir ekran kartı kullandıysanız veya halihazırda kullanıyorsanız, CUDA Çekirdekleri elinizin altında demektir. Peki nedir her gün karşımıza çıkan bu CUDA?
Yeşil takım tarafından geliştirilen grafik yongalarında bulunan işlem birimlerine “CUDA Çekirdeği” adı veriliyor. Açılımı “Compute Unified Device Architecture” olan bu terim, ilk olarak paralel hesaplama yeteneğini ve NVIDIA’nın komut setine erişmemizi sağlayan API’leri tanımlamak için kullanılmaya başladı.
Adı sık sık anılan CUDA Çekirdekleri NVIDIA imzalı GPU’ların bel kemiğidir desek yeridir. İlk olarak 2006 yılında tanıtılan CUDA, o zamandan beri yüksek performanslı bilgi işlemin önemli bir parçası haline geldi. Grafik işlemciler gün geçtikçe çok güçlendi ve CPU’lara yönlendirilen daha fazla iş yükünü üstlenmeye başladı. Özellikle video işleme ve derin öğrenme gibi görevlerde paralel işlemler çok önemlidir. İşte GPU’lar da bu iş için biçilmiş kaftan.

Hadi şimdi CUDA Çekirdeklerinin yapısından ve farklarından konuşalım. Öncesinde ise genel olarak GPU’lardan söz edelim.
GPU’ların Yapısı
Baştan belirtelim, her mimarinin kendine has bir tasarımı vardır. Teknik sayfalarda çekirdek sayıları, ışın izleme birimleri, hesaplama üniteleri ve bellek boyutu gibi birçok detay görürsünüz. Ancak şirketten şirkete, hatta mimariden mimariye çok şey değiyor. Şöyle başlayalım: İki ayrı ekran kartı arasında kıyaslama yaparken çekirdek sayılarına bakarak bir karar veremezsiniz.
AMD, Intel ve NVIDIA gibi şirketler grafik yongalarını tasarlarken tamamen farklı yaklaşımlar benimsemekte. Ayrıca hedef kitleye ve ürün sınıfına göre mimarilerde değişiklikler olabiliyor. Örneğin AMD, üst segment ekran kartları için Navi 31 GPU silikonunu kullanıyor. Bu grafik yongası üst düzey performans isteyenlerin tercih ettiği Radeon RX 7900 serisinde kullanıldı.

Rakip yeşilliler, AD102 grafik çipini premium pazara yönelik olan RTX 4090 serisi için tasarladı. Bu kartların mevcutta bir rakibi yok zira RX 7900 ekran kartları RTX 4080 serisiyle rekabet edebiliyor. Intel’in mevcuttaki en büyük ve güçlü GPU’su ACM-G10 adını taşıyor. Ancak mavi takım pazarda henüz yeni; RTX 3060/RX 6600 gibi ürünlerle rekabet edebiliyorlar.
Ek olarak, NVIDIA nasıl CUDA Çekirdeklerini tasarlıyorsa AMD mühendisleri Stream Processor (SM) ve Intel mühendisleri Xe Core adı verilen çekirdekleri geliştiriyor.
CUDA Çekirdeği Nedir?
CUDA Çekirdekleri, en basit tabirle NVIDIA GPU’larda bulunan paralel işlem birimleridir. Bu çekirdekler, hesaplamalar yaparak ve görevleri CPU ile paralel olarak yürüterek GPU’ların render uygulamaları ile birlikte işlemeye katkıda bulunmasını sağlar. Dahası, CUDA Çekirdekleri CUDA programlama için özel olarak tasarlanmakta. Bu da geliştiricilerin GPU’ların gücünü yalnızca işleme dışında genel amaçlı bilgi işlem görevleri için kullanmasına olanak tanıyor.

CUDA Çekirdekleri verileri eşzamanlı olarak işlemek için birlikte uyum içinde çalışabiliyor, böylelikle geleneksel CPU işlemeye kıyasla hesaplamalar çok daha hızlı hale geliyor. Ayrıca her bir CUDA Çekirdeği aynı anda birden fazla talimat yürütme yeteneğine sahip. Özetle diyebiliriz ki GPU’lar paralel iş yükleri için oldukça verimli.

CUDA Çekirdeklerinin çalışmasını anlamak için bir örnek ele alalım. İşlemciyi bir su deposu olarak düşünün. Eğer depoyu boşaltmak istiyorsanız borulardan yararlanmanız gerek. Eğer daha fazla sayıda boru bağlarsanız, doğal olarak depoyu daha hızlı şekilde boşaltabilirsiniz. NVIDIA’nın çekirdekleri işlemciye giden bu borular gibi hareket eder. Daha fazla sayıda CUDA çekirdeğiyle işlemi daha hızlı bir şekilde gerçekleştirebiliriz.
Modern NVIDIA GPU’lar bildiğiniz üzere üç farklı türde işlem çekirdeği ile birlikte geliyor:
- CUDA çekirdekleri
- Tensor çekirdekleri
- Işın İzleme (Ray Tracing) çekirdekleri
Her çekirdek farklı amaçlara yönel olarak özel şekilde tasarlanmakta. Eğer ilginizi çekiyorsa Tensor ve Ray Tracing Çekirdekleriyle ilgili bilgilere aşağıdaki makalemizden ulaşabilirsiniz. Biz şimdi NVIDIA kartların en temeli olan CUDA Çekirdeklerinden devam edeceğiz.
Yeşil ekip, Tesla, Fermi, Kepler, Maxwell, Pascal, Volta, Turing, Ampere ve Ada Lovelace dahil olmak üzere tüm mimarilerini CUDA Çekirdeklerinin üzerine inşa ediyor. Ancak aynı şey Tensor çekirdekleri veya Ray-Tracing çekirdekleri için söylenemez.
İlk Fermi GPU’lar, her biri 32 çekirdeğe (CUDA) sahip SM’ler (Streaming Multiprocessors) ile tasarlanıyordu. Maksimum 16 SM ile birlikte 512 adede kadar CUDA Çekirdeği birlikte çalışabiliyordu. Ayrıca bu GPU’lar maksimum 6 GB GDDR5 belleği destekliyordu. İşte bir Fermi CUDA Çekirdeğinin yapısını gösteren bir blok diyagramı. Her CUDA Çekirdeğinin bir kayan nokta birimi ve bir tamsayı birimi vardı.
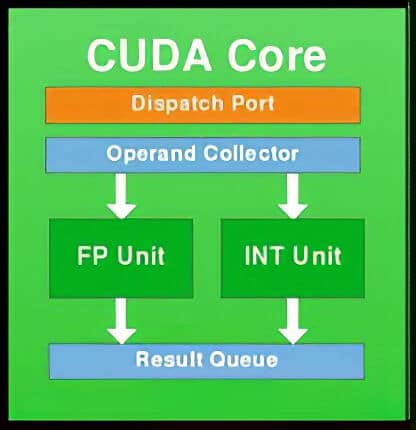
Bir sonraki şekil ise Fermi GPU’ların blok diyagramını gösteriyor. Yani GPU’ya genel bir bakış.

Bildiğiniz gibi şirketler sürekli olarak GPU’ların performansını ve verimliliğini iyileştirmek için çalışmalar yürütüyor. Mimari bazlı gelişimlerde bazen çekirdeklerin sayısı artıyor, bazen performans iyileştirmeleriyle birlikte verimlilik tarafında geliştirmeler yapılıyor. Örneğin Kepler mimarisi ile CUDA Çekirdek sayısı üç katına çıkarılmıştı. Kepler mimarisi 1536 CUDA Çekirdeğini destekliyordu ve 28nm fabrikasyon teknolojisine dayanıyordu.

Bundan sonra NVIDIA her yeni nesilde daha fazla CUDA Çekirdeği eklemeye devam etti. NVIDIA Quadro GP100’ün blok diyagramı böyle görünüyordu. Bu GPU, NVIDIA tarafından 2016 yılında piyasaya sürülen Pascal mimarisinin bir parçasıydı.
Hem Maxwell hem de Pascal mimarileri, akış çoklu işlemcisi (SM) başına 128 CUDA Çekirdeğine sahipti. Maxwell mimarisinde tamsayı birimi kırpılmıştı ve özel çarpma birimi kaldırıldı.
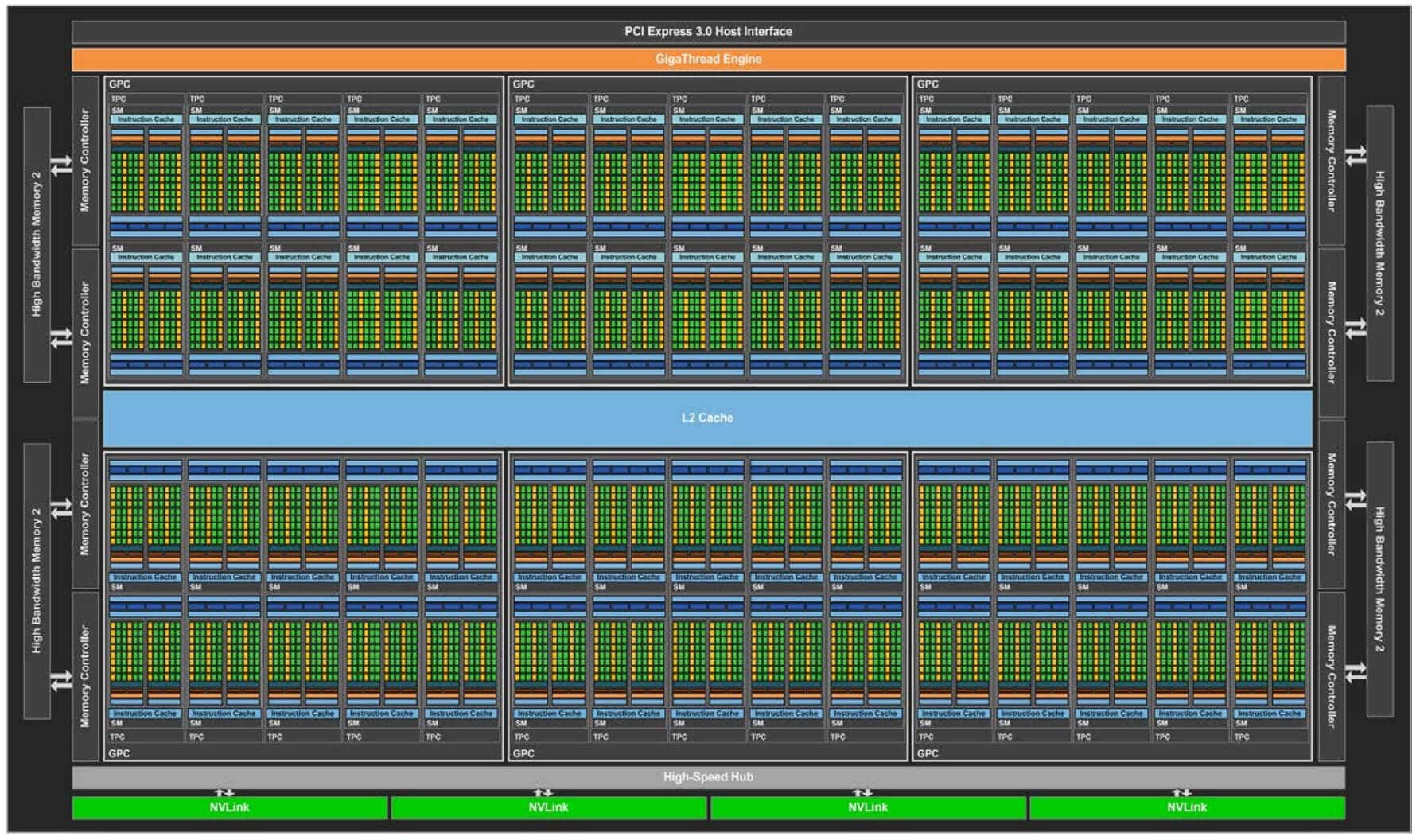
Turing mimarisi GPU’lara pek çok değişiklik getirdi. Örneğin üst sınıf ekran kartlarında kullanılan TU102 GPU’nun blok diyagramı aşağıdaki görünüyordu.
SM başına CUDA Çekirdeği sayısı 64’e düşürüldü (128’den). Tensör çekirdekleri ve Işın İzleme çekirdekleri eklendi. Şirket TSMC’nin 12nm üretim teknolojisine geçiş yaptı. Ayrıca Turing mimarisinden başlayarak tamsayı ve kayan nokta birimleri ayrıldı.

Ampere mimarisi 2. Nesil Işın İzleme Çekirdeklerini getirdi. GA100 GPU’da 128 SM vardı. Ampere GA102 ise 10.752 CUDA Çekirdeğine sahip. Bu kez her çekirdek iki FP32 işlem biriminden (32 bit kayan nokta işlemlerini gerçekleştiren birimler) oluşuyordu.
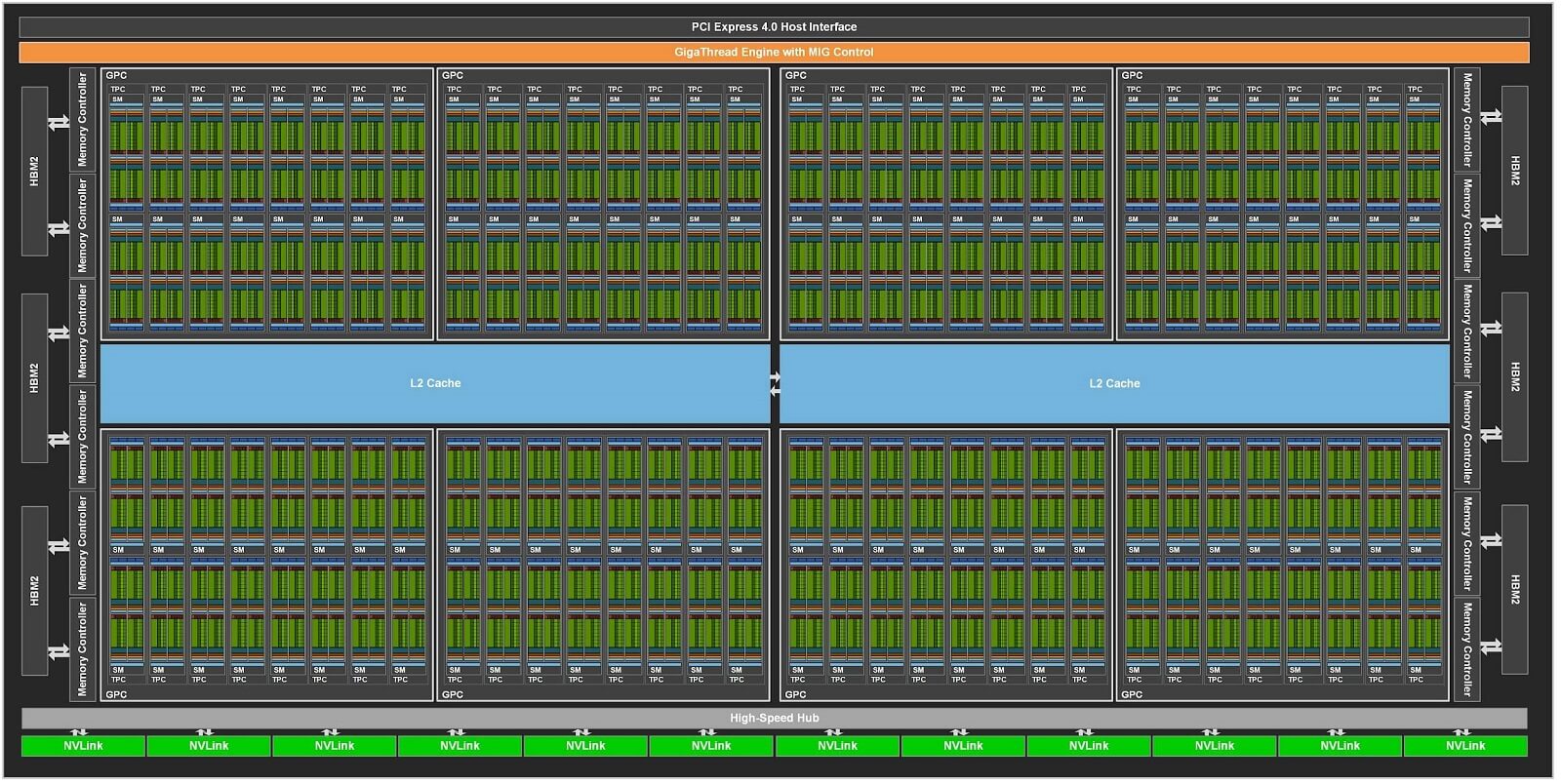
Ampere CUDA Çekirdekleriyle ilgili ilginç olan şey, hem tamsayılar hem de kayan noktalar üzerindeki işlemleri gerçekleştirebilmesi. Bu, Ampere mimarisindeki her CUDA Çekirdeğinin saat döngüsü başına iki FP32 veya bir FP32 ve bir INT işlemini gerçekleştirebileceği anlamına geliyor.
Bu kelimeleri yazarken Ada Lovelace mimarisi yeşil takımın en güçlü kozuydu. NVIDIA, 6 Doku İşleme Kümesi (Texture Processing Cluster-TPC) içeren Grafik İşleme Kümeleriyle (Graphics Processing Cluster-GPC) tasarım sürecine devam ediyor. Bunların her biri Çoklu Akış İşlemcisi (Streaming Multiprocessor-SM) barındırıyor. Yapılandırma Ada Lovelace ile değişmese de toplam rakamlarda değişiklik oldu.

Kırpılmamış AD102 grafik kalıbında GPC sayısı 7’den 12’ye çıktı. Böylelikle toplam 144 SM ve 18.432 CUDA Çekirdeğine sahip bir GPU inşa etmek mümkün hale geldi. Navi 31’in 6144 SP’si ile kıyaslandığında 18.432 devasa bir rakam gibi görünebilir lakin dediğimiz gibi tasarım çok farklı.
Diğer yandan mimaride farklı değişimler de gördük. 3. nesil Ray Tracing çekirdekleriyle birlikte 4. nesil Tensor Çekirdekleri kullanılmaya başladı.
Önceki nesil Ampere ekran kartlarında AV1 kod çözme desteği sunulsa da AV1 kodlama desteği sunulmuyordu. Ada mimarisi üzerine inşa edilen ekran kartları, AV1 kodlama desteği sunan sekizinci nesil NVIDIA Encoder’a (NVENC) sahip.
CUDA Çekirdekleri Neden Önemli?
CUDA Çekirdekleri NVIDIA GPU’ların kalbidir. Bu çekirdekler, hem monitör ve TV gibi görüntüleme cihazları hem de bilgisayarla görme uygulamaları için görüntüleri, videoları ve diğer görsel bilgileri işlemek ve oluşturmak için kullanılmakta.
Her yeni nesil NVIDIA GPU’ları daha güçlü çekirdeklerle geliyor. Şirketin en yeni amiral gemisi GPU’su GeForce RTX 4090, 16.384 CUDA Çekirdeğine sahip. Başka bir deyişle, bir önceki nesle göre yaklaşık %40’lık bir artış sağlandı ve bu çok fazla güç demek!
Çok sayıda CUDA Çekirdeğine sahip GPU’lar, belirli karmaşık hesaplama türlerini daha az çekirdeğe sahip GPU’lara göre çok daha hızlı şekilde gerçekleştirebiliyor. Tek faktör çekirdek sayısı değil elbette, ama en önemli faktör desek yanılmış olmayız. Nitekim CUDA Çekirdekleri bir NVIDIA GPU’nun performansı hakkında yorum yapmak için önemli bir ölçüttür.

Bir özet geçelim. CUDA Çekirdekleri, modern NVIDIA GPU’larının paralel hesaplama iş gücüdür. Dolayısıyla bir GPU’nun performansı üzerinde önemli bir etkiye sahiptirler. Bu çekirdekler GPU’nun yoğun hesaplama gerektiren görevleri CPU’dan alıp CUDA Çekirdekleri üzerinde işlemesini sağlar.
Ayrıca CUDA Çekirdekleri genel amaçlı GPU hesaplamasına (GPGPU) ve grafik oluşturmaya da katkıda bulunur. Bu nedenle, CUDA Çekirdekleri bir ekran kartının performansını büyük ölçüde etkileyen çok önemli bir performans kriteri.
Hangi Görevlerde Kullanılır?
Modern NVIDIA GPU’larda CUDA Çekirdeklerinin rolü çok büyük. Çeşitli diğer görevleri kolaylaştırmanın yanı sıra paralel hesaplama yürütme konusunda da aktif. Bu çekirdeklerin önemli rollerinden bazıları şöyle:
- Paralel İşleme: CUDA Çekirdekleri, paralel işleme görevlerini verimli bir şekilde yerine getirmek için tasarlandı. CPU iş yükü hafifletilirken, GPU’nun aynı anda birden fazla hesaplama yapması sağlanmakta. Dahası, karmaşık hesaplamaların yalnızca CPU tarafından gerçekleştirileceği sürenin çok altında bir sürede yürütülmesi mümkün hale geldi.
- Grafik İşleme: CUDA Çekirdekleri başlangıçta grafik işleme için geliştirildi. Paralel hesaplama dışında GPU tabanlı render işleminin bel kemiği olarak bu çekirdekleri gösterebiliriz. Vertex işleme, piksel gölgeleme, geometri işleme ve doku eşleme gibi grafikle ilgili çeşitli görevler burada gerçekleşiyor. Diğer yandan, CUDA Çekirdekleri gerçekçi 3D grafikler oluşturma konusunda mükemmel ve oyun, sanal gerçeklik ve bilgisayar destekli tasarımda (CAD) akıcı ve sürükleyici görsel deneyimler sağlanıyor.
- Genel Amaçlı GPU Hesaplama (GPGPU): CUDA Çekirdekleri, bilimsel simülasyonlar, makine öğrenimi, veri analitiği ve çok daha fazlasını içeren grafiklerin ötesinde çok çeşitli hesaplama görevlerini hızlandırmak için kullanılabilir. CUDA Çekirdeklerinin paralel işlem gücünden yararlanarak, karmaşık hesaplamalar aynı anda yürütülen daha küçük, paralel görevlere bölünebilir ve bu da olağanüstü performans kazanımları sağlamakta.
- CUDA Araç Seti ve Programlama: Eğer bir geliştiriciyseniz, GPU programlama için programlama modelleri ve kütüphaneler içeren CUDA Toolkit’i kullanabilirsiniz. Bu araç setinin yardımıyla yalnızca CUDA özellikli GPU’larda çalışan kodlar yazabilirsiniz. CUDA Çekirdeklerinin gücünden yararlanabilir ve GPU’ların paralel işleme yeteneklerinin kilidini açabilirsiniz.
CUDA Çekirdekleri Performansı Nasıl Etkiler?
Her NVIDIA GPU yüzlerce veya binlerce CUDA Çekirdeği içeriyor demiştik. İşlem gücü söz konusu olduğunda, bir GPU’nun performansını değerlendirirken göz önünde bulundurulması gereken pek çok şey var. GPU saat hızları, GPU mimarisi, Bellek bant genişliği, Bellek hızı, TMU’lar, VRAM ve ROP’lar GPU performansını etkileyen diğer unsurlardan bazıları.
VRAM, nesneleri, dokuları, gölge haritalarını ve GPU aracılığıyla işlenen diğer tüm verileri tutar. Ekran kartlarının bu verileri VRAM’de saklamasının nedeni, DRAM, SSD veya HDD’ye kıyasla VRAM’den erişmenin çok daha hızlı olması.
Saat hızlarına gelince, tartışmamız gereken iki şey var: çekirdek saati ve bellek saati. Çekirdek saati GPU’nun çalıştığı hızdır. Öte yandan, bellek saati GPU VRAM’inin çalışma hızıdır. Çekirdek saati işlemcinin saat hızına, bellek saati ise sistem RAM’inin hızına benzer.
Ana akım pazardaki CPU’ların çoğu iki ila on altı çekirdekle birlikte geliyor. Çekirdek sayılarındaki artış işlemleri kısmen de olsa paralel olarak gerçekleştirmelerini sağlar. Grafiksel hesaplamalar söz konusu olduğunda paralel olarak hesaplanması gereken çok fazla şey vardır. GPU’lara baktığınızda, çekirdek dediğiniz şey aslında CPU’lar için sadece bir Kayan Nokta Birimidir.
Bir GPU çekirdeği talimatları getiremez veya çözemez, sadece hesaplamaları gerçekleştirir. Bahsettiğimiz çekirdeklerin sayısı modern GPU’larda artık binlerle ifade ediliyor.
Herhangi bir ekran kartının performansını yalnızca CUDA Çekirdeği sayısına göre değerlendirmek mümkün değil. Ekran kartlarının mimarisini, saat hızlarını, CUDA Çekirdeklerinin sayısını ve yukarıda bahsettiğimiz çok daha fazlasını hesaba katmanız gerekiyor.
Aynı nesil içindeki GPU’ları karşılaştıracak olursanız CUDA sayısı iyi bir performans göstergesi olabilir. Örneğin GTX 960 1024 CUDA’ya sahipken, GTX 970 1664 CUDA Çekirdeğine sahip. GTX 970, küçük kardeşi GTX 960’a kıyasla daha fazla CUDA Çekirdeği taşıyor ve çok daha performanslı.
Daha fazla CUDA sayısı, performansı düşüren başka faktörler olmadığı sürece daha iyi performans anlamına geliyor. Farklı nesil ve mimarilere sahip grafik kartlarını karşılaştırdığınızda ise işler biraz karışıyor. Örneğin GTX 1070, GTX 780 ile neredeyse aynı sayıda CUDA Çekirdeğine sahip. Diğer taraftan RTX 2060, GTX 780’e kıyasla daha az CUDA Çekirdeği barındırıyor. Bu rakamlar bildiğiniz gibi GTX 780’in GTX 1070 veya RTX 2060’tan daha üstün olduğunu göstermiyor.

Performanstaki fark, farklı nesil GPU’lar arasındaki farklı mimari, verimlilik iyileştirmeleri, performans gelişimi, komut setleri, transistör boyutu ve üretim süreci nedeniyle ortaya çıkmakta. CUDA Çekirdeğinin performansı büyük ölçüde fabrikasyon boyutuna ve GPU mimarisine bağlı. Özetle diyebiliriz ki, yeni neslin tek bir CUDA Çekirdeği, öncekine kıyasla çok daha güçlü olabilir.
Farklı nesilden iki GPU’yu, Maxwell mimarisine dayanan GTX 980 Ti ve Pascal mimarisine dayanan GTX 1080’i ele alalım:
| GeForce GTX 980 Ti | GeForce GTX 1080 | |
| Transistör Sayısı | 8,100,000,000 | 7,200,000,000 |
| CUDA Sayısı | 2816 | 2560 |
| Transistör/Çekirdek Sayısı | 2,876,420 | 2,812,500 |
| Saat Hızı | 1500 MHz | 2000 MHz |
Yukarıdaki tabloya baktığınızda iki ekran kartı arasında transistör/CUDA Çekirdeği bakımından küçük bir fark olduğunu görebilirsiniz. Eğer rakamlara bakacak olursanız performansın benzer olacağını düşünebilirsiniz, ancak bu yanlış bir çıkarım.
Maxwell mimarisindeki transistörlerin küçük boyutu burada fark yaratan şey. Daha küçük transistörler genel güç tüketimini azaltır ve üreticilerin küçük bir kalıba daha fazla transistör yerleştirmesini sağlar. Tüm bunlar, Pascal GPU’ların ulaşabileceği maksimum saat frekanslarında bir artışa yol açıyor ve bu da genel performansı artırıyor.
GPU’nuzun ne kadar iyi olduğunu bulmak için karmaşık detaylara takılmak yerine gerçek dünyadaki oyun veya hesaplama kıyaslamalarına bakmanızı öneriyoruz. Technopat.Net‘te her segmentten ekran kartının incelemelerini bulabilirsiniz. İşte son nesil NVIDIA ekran kartlarının CUDA değerleri:
| Ekran Kartı | CUDA Çekirdeği Sayısı |
|---|---|
| RTX 4090 | 16384 |
| RTX 4080 | 9728 |
| RTX 4070 Ti | 7680 |
| RTX 4070 | 5888 |
| RTX 4060 Ti | 4352 |
| RTX 4060 | 3072 |
| RTX 3090 Ti | 10752 |
| RTX 3090 | 10496 |
| RTX 3080 Ti | 10240 |
| RTX 3080 | 8960 |
| RTX 3070 Ti | 6144 |
| RTX 3070 | 5888 |
| RTX 3060 Ti | 4864 |
| RTX 3060 | 3584 |







{kind=link}