Pete Castiglione
Hectopat
- Katılım
- 19 Mayıs 2020
- Mesajlar
- 61
- Çözümler
- 1
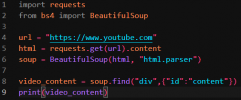
Öncelikle herkese merhaba. BTK Akademi üzerinden aldığım Python eğitim setinin sonlarına yaklaşmaktayım fakat şöyle bir sorunum var: Mesela Beautiful Soup kütüphanesinin syntaxını ve çalışma mantığını bir etiketi nasıl seçebileceğimi biliyorum fakat bir web sitesinden bir bilgi, veri çekeceğim zaman hangi etiketi seçmem gerektiğini bir türlü bulamıyorum, o etikete bir türlü ulaşamıyorum. Sonuç her zaman none. Basit sitelerden scraping yapabiliyorum fakat YouTube ve Hepsiburada gibi kodları biraz daha karmaşık sitelere gelince iş, işte o zaman sonuç her zaman none. Bana yardım edin lütfen. İnternetten bir veriyi çekmek için hangi etiketi seçmem gerektiğini nasıl anlayabilirim?