LinuxGamingGamer
Picopat
- Katılım
- 11 Haziran 2021
- Mesajlar
- 184
- Makaleler
- 1
- Çözümler
- 1
Python'da requests ve beautifulsoup kitaplıklarını kullanarak tek bir web sayfasından resimlerin nasıl ayıklanıp indirileceğini öğrenin.
Hiç belirli bir web sitesinde tüm resimleri indirmek istediniz mi? Bu eğiticide, URL'si verilen bir web sayfasından tüm resimleri getiren bir Python Scraper'ı nasıl inşa edebileceğinizi ve onları requests ve beautifulsoup kitaplıklarını kullanarak nasıl indirebileceğinizi öğreneceksiniz.
Başlamak için birkaç bağımlılığa ihtiyacımız var, hadi onları kuralım:
Yeni bir Python dosyası açın ve gerekli modülleri içe aktarın:
İlk olarak bir URL'nin içine kodlanmış veriyi koyan bazı web siteleri olduğu için, hadi girilen URL'nin geçerli bir URL olduğundan emin olmamızı sağlayan bir URL validatör yapalım, yani bunları atlamamız gerekiyor:
urlparse() fonksiyonu bir URL'yi 6 bileşene ayrıştırır, bizim sadece eğer varsa netloc (domain name) ve scheme (protocol) fonksiyonlarını görmemiz gerekiyor.
İkinci olarak, bir web sitesinin tüm resim URL'lerini yakalayan ana fonksiyonu yazacağım:
Web sayfasının HTML içeriği, soup nesnesindedir. HTML'de tüm img Tag'larını ayrıştırmak için soup. Find_all("img") metodunu kullanmamız gerekiyor, hadi onu fiili olarak görelim:
Bu, tüm img ögelerini bir Python listesi olarak hazırlayacaktır.
Onu, yine de bir ilerleme çubuğu yazdırmak için bir tqdm nesnesi içerisine dahil ettim. İmg Tag'li bir URL yakalamak için, bir src niteliği var. Ancak src niteliğini içermeyen bazı Tag'ler vardır, işte onları yukarıda da görebileceğiniz gibi continue ifadesini kullanarak atlarız.
Şimdi URL'nin net olduğundan emin olmamız gerekiyor:
# Sadece ayıklanan URL ile Domain'e katılarak tam URL'yi almak için.
Pek hoşlanmadığımız ve " /image. PNG? C=3.2.5 " gibi bazı şeylerle sonlanan HTTP get anahtar değeri çiftlerini içeren bazı URL'ler vardır. Hadi şimdi onları silelim:
"?" Karakterinin şeklini alıyoruz, ardından ondan sonraki her şeyi siliyoruz. Eğer hiçbir şey yoksa, valueerror ortaya çıkacaktır. Bu yüzden onu try-except bloğu içerisine gömdüm. Tabbi ki de onu daha iyi bir yoldan geliştirebilirsiniz, eğer geliştirebilirseniz lütfen aşağıdaki yorumlar kısmında bunu bizimle paylaşın.
Hadi şimdi her URL'nin geçerli ve tüm resim veya görüntü URL'lerini dönderdiğinden emin olalım:
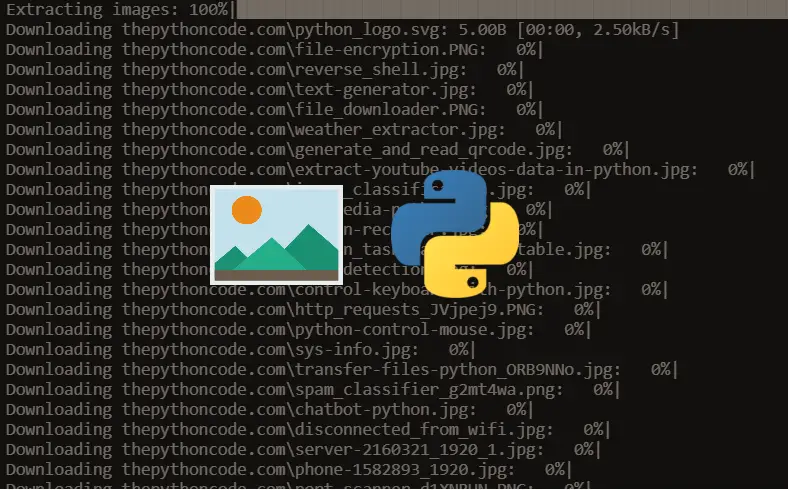
Şimdi tüm resim URL'lerini yakalayan bir fonksiyona sahibiz fakat şimdi de Python ile Web'den dosyaları indirmek için bir fonksiyona ihtiyacımız var. Bu eğitici için aşağıdaki fonksiyonu hazırladım:
Yukarıdaki fonksiyon temel olarak indirmek için dosya URL'sini ve bu dosyayı kaydetmek için klasörün Pathname'ini (dosya yolunu) alır.
Son olarak buradaki ise ana yani main fonksiyonumuzdur:
Hiç belirli bir web sitesinde tüm resimleri indirmek istediniz mi? Bu eğiticide, URL'si verilen bir web sayfasından tüm resimleri getiren bir Python Scraper'ı nasıl inşa edebileceğinizi ve onları requests ve beautifulsoup kitaplıklarını kullanarak nasıl indirebileceğinizi öğreneceksiniz.
Başlamak için birkaç bağımlılığa ihtiyacımız var, hadi onları kuralım:
pip3 install requests bs4 tqdmYeni bir Python dosyası açın ve gerekli modülleri içe aktarın:
import requests.
import os.
from tqdm import tqdm.
from bs4 import BeautifulSoup as bs.
from urllib.parse import urljoin, urlparseİlk olarak bir URL'nin içine kodlanmış veriyi koyan bazı web siteleri olduğu için, hadi girilen URL'nin geçerli bir URL olduğundan emin olmamızı sağlayan bir URL validatör yapalım, yani bunları atlamamız gerekiyor:
def is_valid(url):
"""
URL' nin geçerli bir 'URL' olup olmadığı kontrol ediliyor...
"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)urlparse() fonksiyonu bir URL'yi 6 bileşene ayrıştırır, bizim sadece eğer varsa netloc (domain name) ve scheme (protocol) fonksiyonlarını görmemiz gerekiyor.
İkinci olarak, bir web sitesinin tüm resim URL'lerini yakalayan ana fonksiyonu yazacağım:
def get_all_images(url):
"""
Tek bir url`daki tüm görüntü URL'lerini döndürür.
"""
soup = bs(requests.get(url).content, "html.parser")Web sayfasının HTML içeriği, soup nesnesindedir. HTML'de tüm img Tag'larını ayrıştırmak için soup. Find_all("img") metodunu kullanmamız gerekiyor, hadi onu fiili olarak görelim:
urls = []
for img in tqdm(soup.find_all("img"), "Görüntü çıkarma"):
img_url = img.attrs.get("src")
if not img_url:
# eğer img kaynak niteliğinden yoksunsa sadece atlıyoruz.
continueBu, tüm img ögelerini bir Python listesi olarak hazırlayacaktır.
Onu, yine de bir ilerleme çubuğu yazdırmak için bir tqdm nesnesi içerisine dahil ettim. İmg Tag'li bir URL yakalamak için, bir src niteliği var. Ancak src niteliğini içermeyen bazı Tag'ler vardır, işte onları yukarıda da görebileceğiniz gibi continue ifadesini kullanarak atlarız.
Şimdi URL'nin net olduğundan emin olmamız gerekiyor:
# Sadece ayıklanan URL ile Domain'e katılarak tam URL'yi almak için.
img_url = urljoin(url, img_url)Pek hoşlanmadığımız ve " /image. PNG? C=3.2.5 " gibi bazı şeylerle sonlanan HTTP get anahtar değeri çiftlerini içeren bazı URL'ler vardır. Hadi şimdi onları silelim:
try:
pos = img_url.index("?")
img_url = img_url[:pos]
except ValueError:
pass"?" Karakterinin şeklini alıyoruz, ardından ondan sonraki her şeyi siliyoruz. Eğer hiçbir şey yoksa, valueerror ortaya çıkacaktır. Bu yüzden onu try-except bloğu içerisine gömdüm. Tabbi ki de onu daha iyi bir yoldan geliştirebilirsiniz, eğer geliştirebilirseniz lütfen aşağıdaki yorumlar kısmında bunu bizimle paylaşın.
Hadi şimdi her URL'nin geçerli ve tüm resim veya görüntü URL'lerini dönderdiğinden emin olalım:
# son olarak eğer URL geçerliyse.
if is_valid(img_url):
urls.append(img_url)
return urlsŞimdi tüm resim URL'lerini yakalayan bir fonksiyona sahibiz fakat şimdi de Python ile Web'den dosyaları indirmek için bir fonksiyona ihtiyacımız var. Bu eğitici için aşağıdaki fonksiyonu hazırladım:
def download(url, pathname):
"""
Bir URL verilen dosyayı indirir ve "PathName" klasörüne koyar.
"""
# eğer path mevcut değilse path dir komutunu gerçekleştirir.
if not os.path.isdir(pathname):
os.makedirs(pathname)
# response kalıbını CHUNK ile indirir ama hemen değil.
response = requests.get(url, stream=True)
# toplam dosya boyutunu alır.
file_size = int(response.headers.get("Content-Length", 0))
# dosya ismini alır.
filename = os.path.join(pathname, url.split("/")[-1])
# İlerleme çubuğu, birimi yineleme yerine baytlara değiştirir (varsayılan TQDM dir)
progress = tqdm(response.iter_content(1024), f"İndiriliyor {filename}", total=file_size, unit="B", unit_scale=True, unit_divisor=1024)
with open(filename, "wb") as f:
for data in progress.iterable:
# Dosyaya okunan veriyi yazmak.
f.write(data)
# ilerleme çubuğunu manuel olarak güncellemek.
progress.update(len(data))Yukarıdaki fonksiyon temel olarak indirmek için dosya URL'sini ve bu dosyayı kaydetmek için klasörün Pathname'ini (dosya yolunu) alır.
Son olarak buradaki ise ana yani main fonksiyonumuzdur:
def main(url, path):
# tüm resimleri al.
imgs = get_all_images(url)
for img in imgs:
# herbir resim için onları indir.
download(img, path)
Son düzenleyen: Moderatör:
 yani advanced level...
yani advanced level...